3️⃣ Training Loop
Learning Objectives
- Build a full training loop for the PPO algorithm
- Train our agent, and visualise its performance with Weights & Biases media logger
- Use reward shaping to improve your agent's training (and make it do tricks!)
Writing your training loop
Finally, we can package this all together into our full training loop. The train function has been written for you: it just performs an alternating sequence of rollout & learning phases, a total of args.total_phases times each. You can see in the __post_init__ method of our dataclass how this value was calculated by dividing the total agent steps by the batch size (which is the number of agent steps required per rollout phase).
Your job will be to fill in the logic for the rollout & learning phases. This will involve using many of the functions you've written in the last 2 sections.
Exercise - complete the PPOTrainer class
You should fill in the following methods. Ignoring logging, they should do the following:
rollout_phase- Step the agent through the environment for
num_steps_per_rollouttotal steps, which collectsnum_steps_per_rollout * num_envsexperiences into the replay memory - This will be near identical to yesterday's
add_to_replay_buffermethod
- Step the agent through the environment for
learning_phase- Sample from the replay memory using
agent.get_minibatches(which returns a list of minibatches), this automatically resets the memory - Iterate over these minibatches, and for each minibatch you should backprop wrt the objective function computed from the
compute_ppo_objectivemethod - Note that after each
backward()call, you should also clip the gradients in accordance with detail #11- You can use
nn.utils.clip_grad_norm(parameters, max_grad_norm)for this - see documentation page. Theargsdataclass contains the max norm for clipping gradients
- You can use
- Also remember to step the optimizer and scheduler at the end of the method
- The optimizer should be stepped once per minibatch, but the scheduler should just be stepped once per learning phase (in classic ML, we generally step schedulers once per epoch)
- Sample from the replay memory using
compute_ppo_objective- Handles actual computation of the PPO objective function
- Note that you'll need to compute
logitsandvaluesfrom the minibatch observationminibatch.obs, but unlike in our previous functions this shouldn't be done in inference mode, since these are actually the values that propagate gradients! - Also remember to get the sign correct - our optimizer was set up for gradient ascent, so we should return
total_objective_function = clipped_surrogate_objective - value_loss + entropy_bonusfrom this method
Once you get this working, you should also add logging:
- Log the data for any terminated episodes in
rollout_phase- This should be the same as yesterday's exercise, in fact you can use the same
get_episode_data_from_infoshelper function (we've imported it for you at the top of this file)
- This should be the same as yesterday's exercise, in fact you can use the same
- Log useful data related to your different objective function components in
compute_ppo_objective- Some recommendations for what to log can be found in detail #12
We recommend not focusing too much on wandb & logging initially, just like yesterday. Once again you have the probe environments to test your code, and even after that point you'll get better feedback loops by turning off wandb until you're more confident in your solution. The most important thing to log is the episode length & reward in rollout_phase, and if you have this appearing on your progress bar then you'll be able to get a good sense of how your agent is doing. Even without this and without wandb, videos of your runs will automatically be saved to the folder part3_ppo/videos/run_name, with run_name being the name set at initialization for your PPOTrainer class.
If you get stuck at any point during this implementation, you can look at the solutions or send a message in the Slack channel for help.
class PPOTrainer:
def __init__(self, args: PPOArgs):
set_global_seeds(args.seed)
self.args = args
self.run_name = f"{args.env_id}__{args.wandb_project_name}__seed{args.seed}__{time.strftime('%Y%m%d-%H%M%S')}"
# Accelerated vectorised env, chosen by mode. All three expose the same gym-style
# reset()/step() returning GPU tensors, so PPO never leaves the GPU:
# classic-control -> GPU CartPole; atari -> EnvPool (C++ emulators); mujoco -> Brax (GPU physics).
# (AtariEnvs / BraxEnvs are defined in the Atari / MuJoCo bonus sections.)
self.envs = ENV_DICT[args.mode](args.env_id, args.num_envs, seed=args.seed)
# Define some basic variables from our environment
self.num_envs = self.envs.num_envs
self.action_shape = self.envs.single_action_space.shape
self.obs_shape = self.envs.single_observation_space.shape
# Create our replay memory
self.memory = ReplayMemory(
self.num_envs,
self.obs_shape,
self.action_shape,
args.batch_size,
args.minibatch_size,
args.batches_per_learning_phase,
args.seed,
)
# Create our networks & optimizer
self.actor, self.critic = get_actor_and_critic(self.envs, mode=args.mode)
self.optimizer, self.scheduler = make_optimizer(self.actor, self.critic, args.total_training_steps, args.lr)
# Create our agent
self.agent = PPOAgent(self.envs, self.actor, self.critic, self.memory)
def rollout_phase(self) -> dict | None:
"""
This function populates the memory with a new set of experiences, using self.agent.play_step
to step through the environment. It also returns a dict of data which you can include in
your progress bar postfix.
"""
raise NotImplementedError()
def learning_phase(self) -> None:
"""
This function does the following:
- Generates minibatches from memory
- Calculates the objective function, and takes an optimization step based on it
- Clips the gradients (see detail #11)
- Steps the learning rate scheduler
"""
raise NotImplementedError()
def compute_ppo_objective(self, minibatch: ReplayMinibatch) -> Float[Tensor, ""]:
"""
Handles learning phase for a single minibatch. Returns objective function to be maximized.
"""
raise NotImplementedError()
def log_video(self, phase: int) -> None:
"""Render the first 16 envs of the rollout currently sitting in the replay memory as a 4x4
grid video (drawn with the env's own `draw` method), save it as an HTML <video> under
`args.video_save_path / run_name`, and log it to wandb if enabled. This is what
`video_log_freq` does. It reuses the rollout we just collected, so it costs no extra env
steps; modes whose draw() can't render from observations alone (mujoco) are skipped — use
`record_brax_video` after training instead."""
if self.args.mode == "mujoco" or not callable(getattr(self.envs, "draw", None)):
return
try:
obs = t.stack([o[:16] for o in self.memory.obs], dim=1).cpu() # (16, T, *obs_shape)
dones = t.stack([d[:16] for d in self.memory.terminated], dim=1).cpu() # (16, T)
if self.args.mode == "pendulum": # pendulum's draw() wants the applied torque appended
actions = t.stack([a[:16] for a in self.memory.actions], dim=1).cpu()
obs = t.cat([obs, actions.reshape(*obs.shape[:2], -1)], dim=-1)
cell_w, cell_h = (84, 84) if self.args.mode == "atari" else (160, 120)
video = render_rollout_grid_html(obs, self.envs.draw, dones=dones, cell_w=cell_w, cell_h=cell_h)
video_dir = self.args.video_save_path / self.run_name
video_dir.mkdir(parents=True, exist_ok=True)
(video_dir / f"phase{phase:04d}.html").write_text(video.data)
if self.args.use_wandb:
wandb.log({"rollout_video": wandb.Html(video.data)}, step=self.agent.step)
except Exception as e: # never let visualization break training
print(f"[video log skipped: {e}]")
def train(self) -> None:
if self.args.use_wandb:
wandb.init(
project=self.args.wandb_project_name,
entity=self.args.wandb_entity,
name=self.run_name,
)
wandb.watch([self.actor, self.critic], log="all", log_freq=50)
pbar = tqdm(range(self.args.total_phases), desc=f"training {self.args.mode}")
last_logged_time = time.time() # so we don't update the progress bar too much
data = {}
for phase in pbar:
new_data = self.rollout_phase()
if new_data is not None:
data = new_data
# Periodically render the rollout we just collected as a grid video (must happen here,
# before the learning phase consumes & resets the memory).
if self.args.video_log_freq and (phase % self.args.video_log_freq == 0):
self.log_video(phase)
self.learning_phase()
# Show episode stats (when available) alongside the latest loss components / KL.
if time.time() - last_logged_time > 0.5:
last_logged_time = time.time()
pbar.set_postfix(phase=phase, **data, **getattr(self, "last_metrics", {}))
self.envs.close()
if self.args.use_wandb:
# Remove the watch() forward hooks BEFORE finishing the run: they log to `wandb.run`,
# which becomes None after finish(), so any later forward pass through the networks
# (e.g. rendering a video of the trained agent) would crash with
# "'NoneType' object has no attribute '_log'".
wandb.unwatch((self.actor, self.critic))
wandb.finish()
Solution (simpler, no logging)
def rollout_phase(self) -> dict | None:
for step in range(self.args.num_steps_per_rollout):
infos = self.agent.play_step()
def learning_phase(self) -> None:
minibatches = self.agent.get_minibatches(self.args.gamma, self.args.gae_lambda)
for minibatch in minibatches:
objective_fn = self.compute_ppo_objective(minibatch)
objective_fn.backward()
nn.utils.clip_grad_norm_(
list(self.actor.parameters()) + list(self.critic.parameters()), self.args.max_grad_norm
)
self.optimizer.step()
self.optimizer.zero_grad()
self.scheduler.step()
def compute_ppo_objective(self, minibatch: ReplayMinibatch) -> Float[Tensor, ""]:
logits = self.actor(minibatch.obs)
dist = Categorical(logits=logits)
values = self.critic(minibatch.obs).squeeze()
clipped_surrogate_objective = calc_clipped_surrogate_objective(
dist, minibatch.actions, minibatch.advantages, minibatch.logprobs, self.args.clip_coef
)
value_loss = calc_value_function_loss(values, minibatch.returns, self.args.vf_coef)
entropy_bonus = calc_entropy_bonus(dist, self.args.ent_coef)
total_objective_function = clipped_surrogate_objective - value_loss + entropy_bonus
return total_objective_function
Solution (full, with logging)
def rollout_phase(self) -> dict | None:
data = None
t0 = time.time()
for step in range(self.args.num_steps_per_rollout):
# Play a step, returning the infos dict (containing information for each environment)
infos = self.agent.play_step()
# Get data from environments, and log it if some environment did actually terminate
new_data = get_episode_data_from_infos(infos)
if new_data is not None:
data = new_data
if self.args.use_wandb:
wandb.log(new_data, step=self.agent.step)
if self.args.use_wandb:
wandb.log(
{"SPS": (self.args.num_steps_per_rollout * self.num_envs) / (time.time() - t0)}, step=self.agent.step
)
return data
def learning_phase(self) -> None:
minibatches = self.agent.get_minibatches(self.args.gamma, self.args.gae_lambda)
for minibatch in minibatches:
objective_fn = self.compute_ppo_objective(minibatch)
objective_fn.backward()
nn.utils.clip_grad_norm_(
list(self.actor.parameters()) + list(self.critic.parameters()), self.args.max_grad_norm
)
self.optimizer.step()
self.optimizer.zero_grad()
self.scheduler.step()
def compute_ppo_objective(self, minibatch: ReplayMinibatch) -> Float[Tensor, ""]:
logits = self.actor(minibatch.obs)
dist = Categorical(logits=logits)
values = self.critic(minibatch.obs).squeeze()
clipped_surrogate_objective = calc_clipped_surrogate_objective(
dist, minibatch.actions, minibatch.advantages, minibatch.logprobs, self.args.clip_coef
)
value_loss = calc_value_function_loss(values, minibatch.returns, self.args.vf_coef)
entropy_bonus = calc_entropy_bonus(dist, self.args.ent_coef)
total_objective_function = clipped_surrogate_objective - value_loss + entropy_bonus
with t.inference_mode():
newlogprob = dist.log_prob(minibatch.actions)
logratio = newlogprob - minibatch.logprobs
ratio = logratio.exp()
approx_kl = (ratio - 1 - logratio).mean().item()
clipfracs = [((ratio - 1.0).abs() > self.args.clip_coef).float().mean().item()]
if self.args.use_wandb:
wandb.log(
dict(
total_steps=self.agent.step,
values=values.mean().item(),
lr=self.scheduler.optimizer.param_groups[0]["lr"],
value_loss=value_loss.item(),
clipped_surrogate_objective=clipped_surrogate_objective.item(),
entropy=entropy_bonus.item(),
approx_kl=approx_kl,
clipfrac=np.mean(clipfracs),
),
step=self.agent.step,
)
return total_objective_function
Here's some code to run your model on the probe environments (and assert that they're all working fine).
A brief recap of the probe environments, along with recommendations of where to go to debug if one of them fails (note that these won't be true 100% of the time, but should hopefully give you some useful direction):
- Probe 1 tests basic learning ability. If this fails, it means the agent has failed to learn to associate a constant observation with a constant reward. You should check your loss functions and optimizers in this case.
- Probe 2 tests the agent's ability to differentiate between 2 different observations (and learn their respective values). If this fails, it means the agent has issues with handling multiple possible observations.
- Probe 3 tests the agent's ability to handle time & reward delay. If this fails, it means the agent has problems with multi-step scenarios of discounting future rewards. You should look at how your agent step function works.
- Probe 4 tests the agent's ability to learn from actions leading to different rewards. If this fails, it means the agent has failed to change its policy for different rewards, and you should look closer at how your agent is updating its policy based on the rewards it receives & the loss function.
- Probe 5 tests the agent's ability to map observations to actions. If this fails, you should look at the code which handles multiple timesteps, as well as the code that handles the agent's map from observations to actions.
def test_probe(probe_idx: int):
"""
Tests a probe environment by training a network on it & verifying that the value functions are
in the expected range.
"""
# Train our network
args = PPOArgs(
env_id=f"Probe{probe_idx}-v0",
mode="probe", # use the GPU (tensor-native) probe envs, so PPOTrainer's GPU agent can run them
wandb_project_name=f"test-probe-{probe_idx}",
total_timesteps=30_000, #adjust up if needed to make tests pass
num_envs=256,
num_steps_per_rollout=8,
num_minibatches=4,
lr=0.01, # also maybe adjust this
video_log_freq=None,
use_wandb=False,
)
trainer = PPOTrainer(args)
trainer.train()
agent = trainer.agent
# Get the correct set of observations, and corresponding values we expect
obs_for_probes = [[[0.0]], [[-1.0], [+1.0]], [[0.0], [1.0]], [[0.0]], [[0.0], [1.0]]]
expected_value_for_probes = [
[[1.0]],
[[-1.0], [+1.0]],
[[args.gamma], [1.0]],
[[1.0]],
[[1.0], [1.0]],
]
expected_probs_for_probes = [None, None, None, [[0.0, 1.0]], [[1.0, 0.0], [0.0, 1.0]]]
tolerances = [1e-3, 1e-3, 1e-3, 2e-3, 2e-3]
obs = t.tensor(obs_for_probes[probe_idx - 1]).to(device)
# Calculate the actual value & probs, and verify them
with t.inference_mode():
value = agent.critic(obs)
probs = agent.actor(obs).softmax(-1)
expected_value = t.tensor(expected_value_for_probes[probe_idx - 1]).to(device)
t.testing.assert_close(value, expected_value, atol=tolerances[probe_idx - 1], rtol=0)
expected_probs = expected_probs_for_probes[probe_idx - 1]
if expected_probs is not None:
t.testing.assert_close(probs, t.tensor(expected_probs).to(device), atol=tolerances[probe_idx - 1], rtol=0)
print("Probe tests passed!\n")
for probe_idx in range(1, 6):
test_probe(probe_idx)
Once you've passed the tests for all 5 probe environments, you should test your model on Cartpole.
See an example wandb run you should be getting here.
args = PPOArgs(use_wandb=True, video_log_freq=50)
trainer = PPOTrainer(args)
trainer.train()
display(record_grid_video(trainer, kind="classic-control"))
Question - if you've done this correctly (and logged everything), clipped surrogate objective will be close to zero. Does this mean that this term is not the most important in the objective function?
No, this doesn't necessarily mean that the term is unimportant.
Clipped surrogate objective is a moving target. At each rollout phase, we generate new experiences, and the expected value of the clipped surrogate objective will be zero (because the expected value of advantages is zero). But this doesn't mean that differentiating clipped surrogate objective wrt the policy doesn't have a large gradient! It's the gradient of the objective function that matters, not the value.
As we make update steps in the learning phase, the policy values $\pi(a_t \mid s_t)$ will increase for actions which have positive advantages, and decrease for actions which have negative advantages, so the clipped surrogate objective will no longer be zero in expectation. But (thanks to the fact that we're clipping changes larger than $\epsilon$) it will still be very small.
Reward Shaping
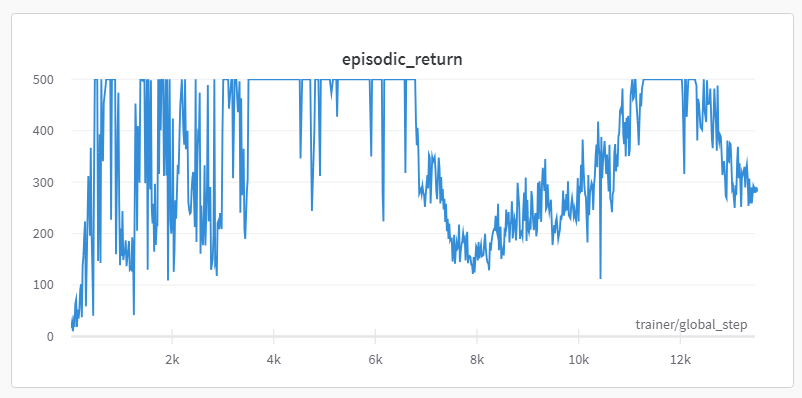
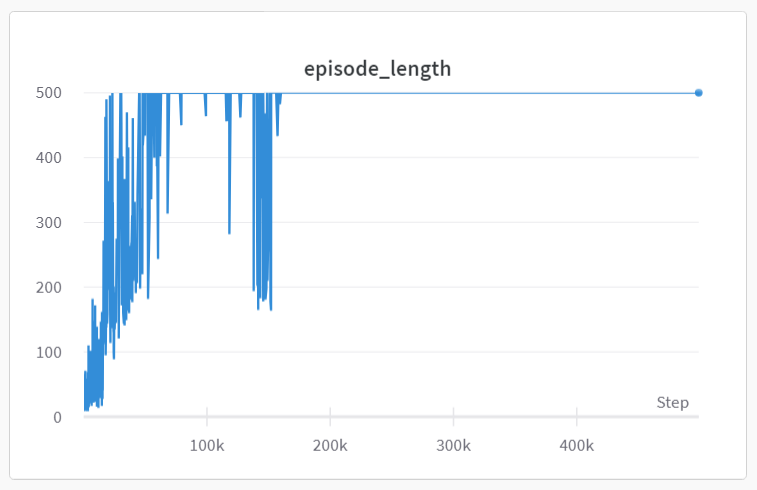
Yesterday during DQN, we covered catastrophic forgetting - this is the phenomena whereby the replay memory mostly contains successful experiences, and the model forgets how to adapt or recover from bad states. In fact, you might find it even more severe here than for DQN, because PPO is an on-policy method (we generate a new batch of experiences for each learning phase) unlike DQN. Here's an example reward trajectory from a PPO run on CartPole, using the solution code:
A small tangent: on-policy vs off-policy algorithms
In RL, an algorithm being on-policy means we learn only from the most recent trajectory of experiences, and off-policy involves learning from a sampled trajectory of past experiences.
It's common to describe PPO as on-policy (because it generates an entirely new batch of experiences each learning phase) and DQN as off-policy (because its replay buffer effectively acts as a memory bank for past experiences). However, it's important to remember that the line between these two can become blurry. As soon as PPO takes a single learning step it technically ceases to be on-policy because it's now learning using data generated from a slightly different version of the current policy. However, the fact that PPO uses clipping to explicitly keep its current and target policies close together is another reason why it's usually fine to refer to it as an on-policy method, unlike DQN.
We can fix catastrophic forgetting in the same way as we did yesterday (by having our replay memory keep some fraction of bad experiences from previous phases), but here we'll introduce another option - reward shaping.
The rewards for CartPole encourage the agent to keep the episode running for as long as possible (which it then needs to associate with balancing the pole), but we can modify the reward to help the agent learn faster. Our GPU CartPole was designed for exactly this: reward_function is a separate method that step calls, so reward shaping is just a subclass that overrides this one method — the physics in step is untouched.
Try to modify the reward to make the task as easy to learn as possible. Compare this against your performance on the original environment, and see if the agent learns faster with your shaped reward. If you can bound the reward on each timestep between 0 and 1, this will make comparing the results to CartPole-v1 easier.
Help - I'm not sure what I'm meant to return in this function.
reward_function is called by step just after the physics update, so self.state holds the new state: a (num_envs, 4) tensor whose columns are [x, v, theta, omega]. The default implementation returns +1 for every env where the pole is still up (and 0 on the terminal step).
Your version should return a (num_envs,) reward tensor computed from self.state, which incentivises good behaviour even if the pole hasn't fallen yet.
Help - I'm confused about how to choose a reward function. (Try and think about this for a while before looking at this dropdown.)
Right now, the agent always gets a reward of 1 for each timestep it is active. You should try and change this so that it gets a reward between 0 and 1, which is closer to 1 when the agent is performing well / behaving stably, and equals 0 when the agent is doing very poorly.
The variables we have available to us are cart position, cart velocity, pole angle, and pole angular velocity, which I'll denote as $x$, $v$, $\theta$ and $\omega$.
Here are a few suggestions which you can try out: * $r = 1 - (\theta / \theta_{\text{max}})^2$. This will have the effect of keeping the angle close to zero. * $r = 1 - (x / x_{\text{max}})^2$. This will have the effect of pushing it back towards the centre of the screen (i.e. it won't tip and fall to the side of the screen).
You could also try using e.g. $|\theta / \theta_{\text{max}}|$ rather than $(\theta / \theta_{\text{max}})^2$. This would still mean reward is in the range (0, 1), but it would result in a larger penalty for very small deviations from the vertical position.
You can also try a linear combination of two or more of these rewards!
Help - my agent's episodic return is smaller than it was in the original CartPole environment.
This is to be expected, because your reward function is no longer always 1 when the agent is upright. Both your time-discounted reward estimates and your actual realised rewards will be less than they were in the cartpole environment.
For a fairer test, measure the length of your episodes (the episode_length readout on the training progress bar) - hopefully your agent learns how to stay upright for the entire 500 timestep interval as fast as or faster than it did previously.
Note - if you want to use the maximum possible values of x and theta in your reward function (to keep it bounded between 0 and 1) then you can. These values can be found at the documentation page (note - the table contains the max possible values, not max unterminated values - those are below the table). You can also use self.x_threshold and self.theta_threshold_radians to get these values directly (again, see the source code for how these are calculated).
Exercise - implement reward shaping
See this link for what an ideal wandb run here should look like (using the reward function in the solutions).
def cartpole_reward_function(self, action: Tensor) -> Tensor:
"""Shaped reward for CartPole. Called by `step` just after the physics update, so `self.state`
is the new (num_envs, 4) state tensor with columns [x, v, theta, omega]. Should return a
(num_envs,) reward tensor (ideally bounded in [0, 1], for easier comparison with the unshaped
env)."""
x, v, theta, omega = self.state.unbind(-1) # each (num_envs,): position, velocity, angle, angular velocity
raise NotImplementedError()
class EasyCart(CartPole):
def reward_function(self, action):
return cartpole_reward_function(self, action)
# Swap the shaped env into ENV_DICT so `mode="classic-control"` builds it (we restore the
# unshaped CartPole afterwards). `env_id` is just a label for the run name.
ENV_DICT["classic-control"] = EasyCart
args = PPOArgs(env_id="EasyCart", use_wandb=True, video_log_freq=50)
trainer = PPOTrainer(args)
trainer.train()
ENV_DICT["classic-control"] = CartPole
display(record_grid_video(trainer, kind="classic-control"))
Solution (one possible implementation)
I tried out a few different simple reward functions here. One of the best ones I found used a mix of absolute value penalties for both the angle and the horizontal position (this outperformed using absolute value penalty for just one of these two). My guess as to why this is the case - penalising by horizontal position helps the agent improve its long-term strategy, and penalising by angle helps the agent improve its short-term strategy, so both combined work better than either on their own.
def cartpole_reward_function(self, action: Tensor) -> Tensor:
x, v, theta, omega = self.state.unbind(-1) # each (num_envs,): position, velocity, angle, angular velocity
# First reward: angle should be close to zero
reward_1 = 1 - (theta / 0.2095).abs()
# Second reward: position should be close to the center
reward_2 = 1 - (x / 2.4).abs()
# Combine both rewards (keep it in the [0, 1] range)
return (reward_1 + reward_2) / 2
The result:
To illustrate the point about different forms of reward optimizing different kinds of behaviour - below are links to three videos generated during the WandB training, one of just position penalisation, one of just angle penalisation, and one of both. Can you guess which is which?
Answer
* First video = angle penalisation * Second video = both (from the same video as the loss curve above) * Third video = position penalisationNow, change the environment such that the reward incentivises the agent to spin very fast. You may also change the termination condition of the environment (it's the env's separate terminated method, so you can override that too) if you think this will help — e.g. letting the pole rotate all the way around without ending the episode.
See this link for what an ideal wandb run here should look like (using the reward function in the solutions).
def spin_cart_reward_function(self, action: Tensor) -> Tensor:
"""Reward for the spinning-cart task. Like `cartpole_reward_function`, this is called by `step`
after the physics update (`self.state` is the new (num_envs, 4) tensor [x, v, theta, omega])
and should return a (num_envs,) reward tensor."""
x, v, theta, omega = self.state.unbind(-1) # each (num_envs,): position, velocity, angle, angular velocity
raise NotImplementedError()
class SpinCart(CartPole):
def reward_function(self, action):
return spin_cart_reward_function(self, action)
def terminated(self):
# Allow full 360-degree rotation: unlike the parent class, only terminate when the cart
# leaves the track (the pole angle no longer ends the episode).
x = self.state[:, 0]
return x.abs() > self.x_threshold
ENV_DICT["classic-control"] = SpinCart
args = PPOArgs(env_id="SpinCart", use_wandb=True, video_log_freq=50)
trainer = PPOTrainer(args)
trainer.train()
ENV_DICT["classic-control"] = CartPole # restore the unshaped env
display(record_grid_video(trainer, kind="classic-control"))
Solution (one possible implementation)
def spin_cart_reward_function(self, action: Tensor) -> Tensor:
x, v, theta, omega = self.state.unbind(-1) # each (num_envs,): position, velocity, angle, angular velocity
# Reward function incentivises fast spinning while staying still & near centre
rotation_speed_reward = (0.1 * omega.abs()).clamp(max=1.0)
stability_penalty = ((x / 2.5).abs() + (v / 10).abs()).clamp(min=1.0)
return rotation_speed_reward - 0.5 * stability_penalty
Note that SpinCart also overrides terminated (the env's separate termination method) so the episode only ends when the cart leaves the track which allows for full 360-degree rotation of the pole.
Another thing you can try is "dancing". It's up to you to define what qualifies as "dancing" - work out a sensible definition, and the reward function to incentive it.