1️⃣ RLHF on transformer language models
Learning Objectives
- Understand how the RL agent / action / environment paradigm works in the context of autoregressive transformer models
- Understand how the RLHF algorithm works, and how it fits on top of PPO
- Learn about value heads, and how they can be used to turn transformers into actor & critic networks with shared architectures
- Write a full RLHF training loop, and use it to train your transformer with the "maximize output of periods" reward function
- Observe and understand the instances of mode collapse that occur when training with this reward function
- Experiment with different reward functions & training hyperparameters
The "transformer environment"
We'll start by discussing how we apply the reinforcement learning framework of states/actions/rewards to the setting of autoregressive language modelling. Lots of our intuitions should carry over from yesterday, it's just some of the details that have changed!
States, actions and episodes
Our actor is an autoregressive language model. The actions $a_t$ are the tokens generated by the model (i.e. the action space is the model's vocabulary). The states $s_t$ are the entire sequence up to that point (not just the most recent token). In other words, given a state $s_t$ (sequence) and action $a_t$ (token generation), our new state is the concatenation which we'll denote as $s_{t+1} = [s_t \; a_t]$. For every timestep before the end of the episode, the reward is zero, and for the final timestep, the reward is given by the reward function, given the entire sequence $r_T = R(s_T)$.
Each episode is a fixed length (i.e. all our sampled outputs will have the same number of tokens generated from them). Each episode starts with an initial "prefix prompt", which is chosen before the start of training. This means that discoutning would only scale the final reward by a fixed constant, and so we don't need to worry about it here.
Rewards and value functions
The reward $r_T$ is a function of the sequence $s_T$. Sometimes it will be a very simple function like the sum of periods . in the sequence, other times it'll get a bit more complicated (e.g. using a text classification model to estimate the sentiment of a sequence - we'll do this later!).
In our case, we'll only evaluate the reward at the end of the episode. This means we don't really have a concept of discount factors here - the reward only comes once, and as soon as it comes our episode terminates.
The value function $V(s_t)$ is an estimate of the expected sum of future rewards (up to the end of the episode), which in this case means it's an estimate of what the reward $r_T$ will be once we get to the end of the sequence. We'll be adding a value head to our transformer model to estimate this value function (more on this later).
Note - a key part of RLHF is the actual gathering of and learning from human feedback, in order to train the reward function. We're not going to be doing that here, instead we'll be working with a fixed reward function. This means our implementation today is a lot more like classical reinforcement learning, and we'll be able to structure it in a way which is very similar to yesterday's PPO implementation.
~~Generalized~~ Advantage Estimation
We won't be using the GAE formula today for computing advantages, we'll just be directly computing it via $A(s_t, a_t) = Q(s_t, a_t) - V(s_t)$, where $a_t$ is the action which was actually taken and $Q(s_t, a_t)$ is the critic's estimate of the value function at this new state $s_{t+1} = [s_t \; a_t]$.
We can get away with this because our setup has pretty low variance when it comes to the advantage of particular actions. GAE is most helpful when it reduces variance in the advantage estimation (it does this at the cost of introducing more bias from including future value function estimates), and so it's especially useful when our environment is one with high variability when the advantage (and optimal policy) changes significantly between steps. But this doesn't really apply to us, since every action just adds a single token onto our sequence.
That said, you're welcome to experiment with the setup and try to use GAE instead! This is suggested as a bonus exercise at the end.
![]()
RLHF Setup
With this context in mind, we're now ready to look at the full RLHF setup we'll be using:
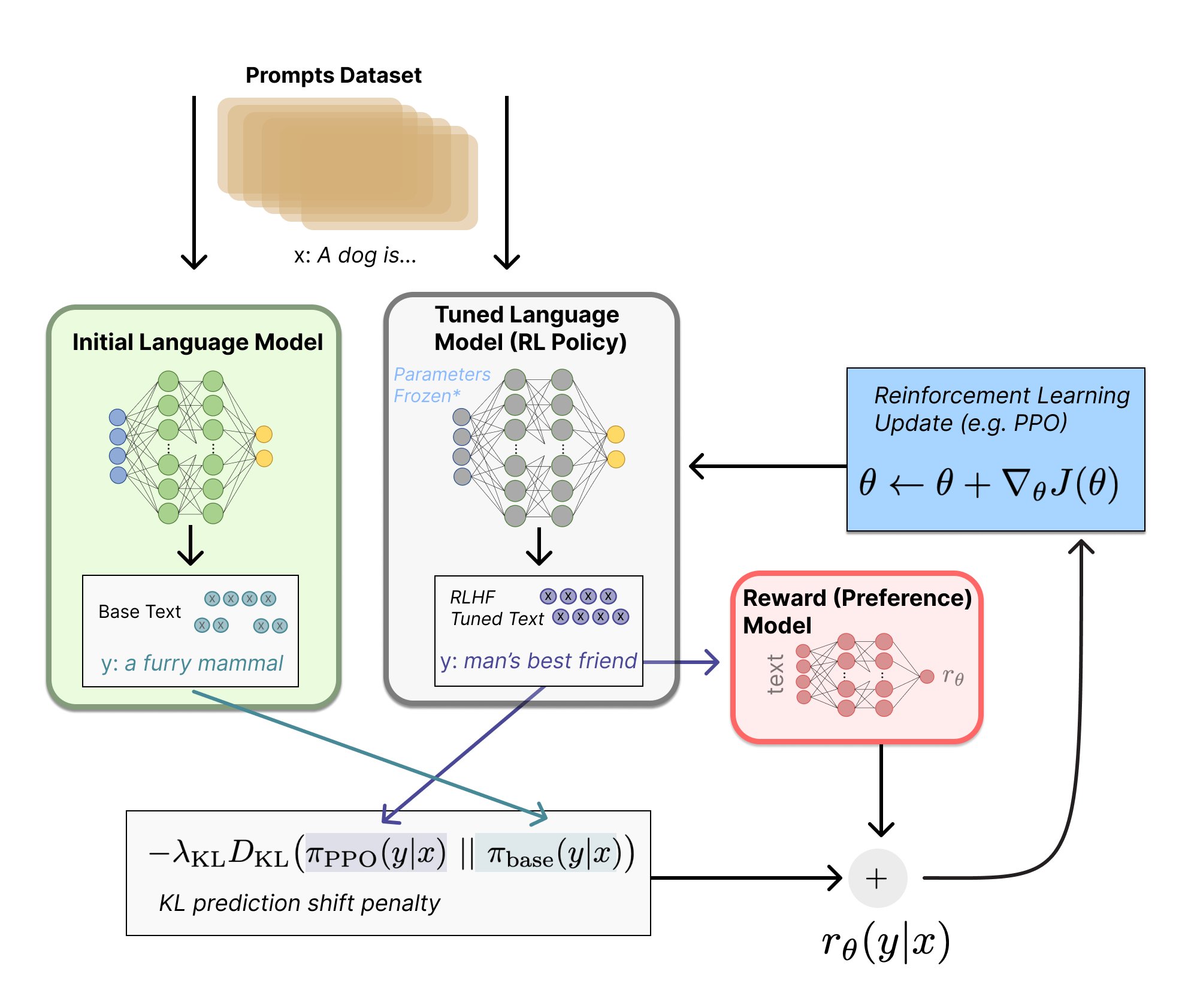
Our autoregressive transformer model (we'll be using GPT2-Small) is the actor, and its value head will play the role of the critic. We follow the standard PPO setup:
- In rollout phase, the actor generates a bunch of sequences all starting from the prefix prompt. We compute advantage estimates using the critic network (value head) and store the experiences in memory.
- In learning phase, we sample from these generated experiences (i.e. from a bunch of generated sequences of different lengths, some of which might be prefixes of each other). We compute our objective function (which is the sum of the same 3 terms as yesterday) and perform a gradient step wrt it.
The only new element is the KL prediction shift penalty. This is a penalty we add to our overall loss function to stop the transformer from diverging too much from its initial distribution. We want to make our transformer maximize reward, but not in a way which causes it to become completely incoherent!
Note that we compute $D_{KL}(\pi_{PPO} || \pi_{base})$, not the other way around. This is because we want to penalize our new model for generating outputs which would be extremely unlikely under the old model, i.e. when $\pi_{PPO}$ is high and $\pi_{base}$ is low. We generally want to focus our model's output into a more concentrated version of the distribution it already has. For example in RLHF, we want to keep a low probability on completely incoherent behaviour which the original model would never have generated. But on the other hand, it's clearly fine for there to be some behaviours (e.g. offensive hate speech) which have a nontrivial probability in our base model but near-zero probability in our new model - in fact this is often desireable! For more on the intuition behind this orientation of the distributions in KL divergence, see this post.
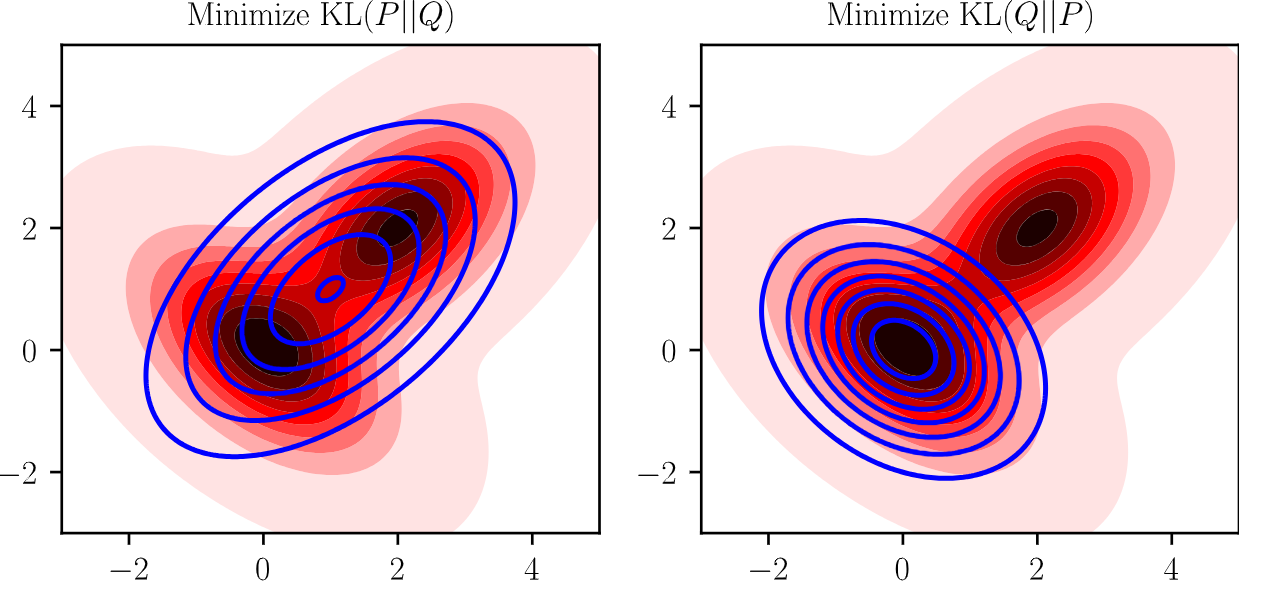
KL divergence v.s. reverse KL divergence
Assume $P$ is the true distribution, and $Q$ is the distribution we're trying to fit to $P$.
-
$D_{KL}(P || Q) = \sum_x P(x) \log \frac{P(x)}{Q(x)}$ blows up when $Q(x)$ is zero and $P(x)$ is positive, so we would expect that $Q$ tries to "cover" $P$ anywhere where $P(x)$ is positive. This means that minimizing $D_{KL}(\pi_{base} || \pi_{PPO})$ will cause our model to be able to do everything the base model can do, plus it can also do things out-of-distribution for the base model, which is undesirable.
-
$D_{KL}(Q || P) = \sum_x Q(x) \log \frac{Q(x)}{P(x)}$ blows up when $P(x)$ is zero and $Q(x)$ is positive, so $Q$ should never assign any probability mass to something that $P$ doesn't ($P$ "covers" $Q$), but $Q$ will instead try to cover a subset of $P$ that it fits the best.
This can be illustrated with an example. Let $P$ be a mixture of two Gaussians, and $Q \sim \mathcal{N}(\mu, \sigma^2)$ be a unimodal Gaussian (blue) parameterized by $\mu$ and $\sigma^2$. We learn parameters $\mu,\sigma^2$ that minimize both $D_{KL}(P || Q)$ and $D_{KL}(Q || P)$, and draw the resulting distribution $Q$ (here in blue), showing the expected behaviour.
Summary
Since we're using a fixed reward function rather than training it from human feedback, our RLHF implementation looks very similar to yesterday's PPO implementation. The differences are summarized in the table below:
| PPO (general) | RLHF | |
|---|---|---|
| States | Contains partial knowledge of our environment | Sequence of tokens up to this point (and the model's internal state representation of that sequence) |
| Actions | Something our agent can do to change its state | Generating a new token, taking us to state $s_{t+1} = [s_t \; a_t]$ |
| Rewards | A function of the state, which is computed after each new state is reached | A function of the sequence, can be computed after each new token but we'll just compute it once at the end of the sequence |
| Multiple steps in parallel? | Yes, we used SyncVectorEnv to parallelize the rollout phase |
Yes, we'll pass batches of sequences into the transformer model, generating multiple new tokens at once |
| Actor & critic networks | Architectures can be shared (e.g. for Atari) or disjoint (e.g. for CartPole) | Actor is a transformer model, critic is a value head (so most architecture is shared) |
| Advantage estimation | Use GAE with discount factor $\lambda$ | Often uses GAE, but we'll just use simple next-step difference $V(s_{t+1}) - V(s_t)$ |
| Anything extra? | KL penalty on the new policy wrt the baseline policy |
RLHF training args
Now that you have a rough idea of how our implementation differs from PPO, we'll give you the RLHFArgs class and highlight the differences between this and the PPOArgs class from yesterday (mostly it's quite similar).
- We're now using
total_phasesto control how long our training lasts for, rather than usingtotal_timesteps. This makes more sense for us, because the total number of timesteps (= number of actions we take = number of tokens we generate) will vary depending on the length of the sequences we generate. - We've removed the arguments
gammaandgae_lambdafor computing the advantage function, since as discussed we'll be computing the advantage in a simpler and more direct way (you'll do this in the next exercise). - We've added the following arguments related to the base model & text sampling:
base_model, for specifying different base models (default is"gpt2-small")gen_len, the length of the sequences we generate.temperatureandtop_k, for controlling the sampling temperature of our sequences.prefix, the string we use to generate all samples.
- As well as the following extra RLHF-specific arguments:
kl_coef, for controlling the strength of the KL prediction shift penalty.reward_fn, for the reward function we use.normalize_reward, for whether we normalize the reward (this won't always be necessary).
- We've also added two learning rates, since it makes sense to have a different learning rate for our value head and the rest of the model (more on this later!).
# Set default parameters for low GPU memory usage, change if you have more GPU memory
LOW_GPU_MEM = True
BASE_MODEL = "gpt2-small" if LOW_GPU_MEM else "gpt2-medium"
RUN_BASE_RLHF = True
@dataclass
class RLHFArgs:
# Basic / global
seed: int = 1
# Wandb / logging
use_wandb: bool = False
wandb_project_name: str = "RLHF"
wandb_entity: str | None = None
# Duration of different phases
total_phases: int = 100
batch_size: int = 128
num_minibatches: int = 4
batches_per_learning_phase: int = 2
# Optimization hyperparameters
base_lr: float = 2e-5
head_lr: float = 5e-4
max_grad_norm: float = 1.0
warmup_steps: int = 20
final_scale: float = 0.1
# Computing other PPO loss functions
clip_coef: float = 0.2
vf_coef: float = 0.15
ent_coef: float = 0.001
# Base model & sampling arguments
base_model: str = BASE_MODEL
gen_len: int = 30
temperature: float = 1.0
top_k: int = 10
prefix: str = "This is"
prepend_bos: bool = True
# RLHF-specific arguments
kl_coef: float = 2.5
reward_fn: Callable = lambda x: 0.0
normalize_reward: bool = True
def __post_init__(self):
assert self.total_phases > self.warmup_steps, "total_phases must be greater than warmup_steps"
assert self.batch_size % self.num_minibatches == 0, "batch_size should be divisible by num_minibatches"
self.minibatch_size = self.batch_size // self.num_minibatches
Value head
If you worked on the Atari exercises yesterday, then you'l be used to the idea of having shared architecture between our policy and value networks. Intuitively, this is because both networks need to learn some kind of high-level encoding of the important variables in the environment - they just do different things with this encoding.
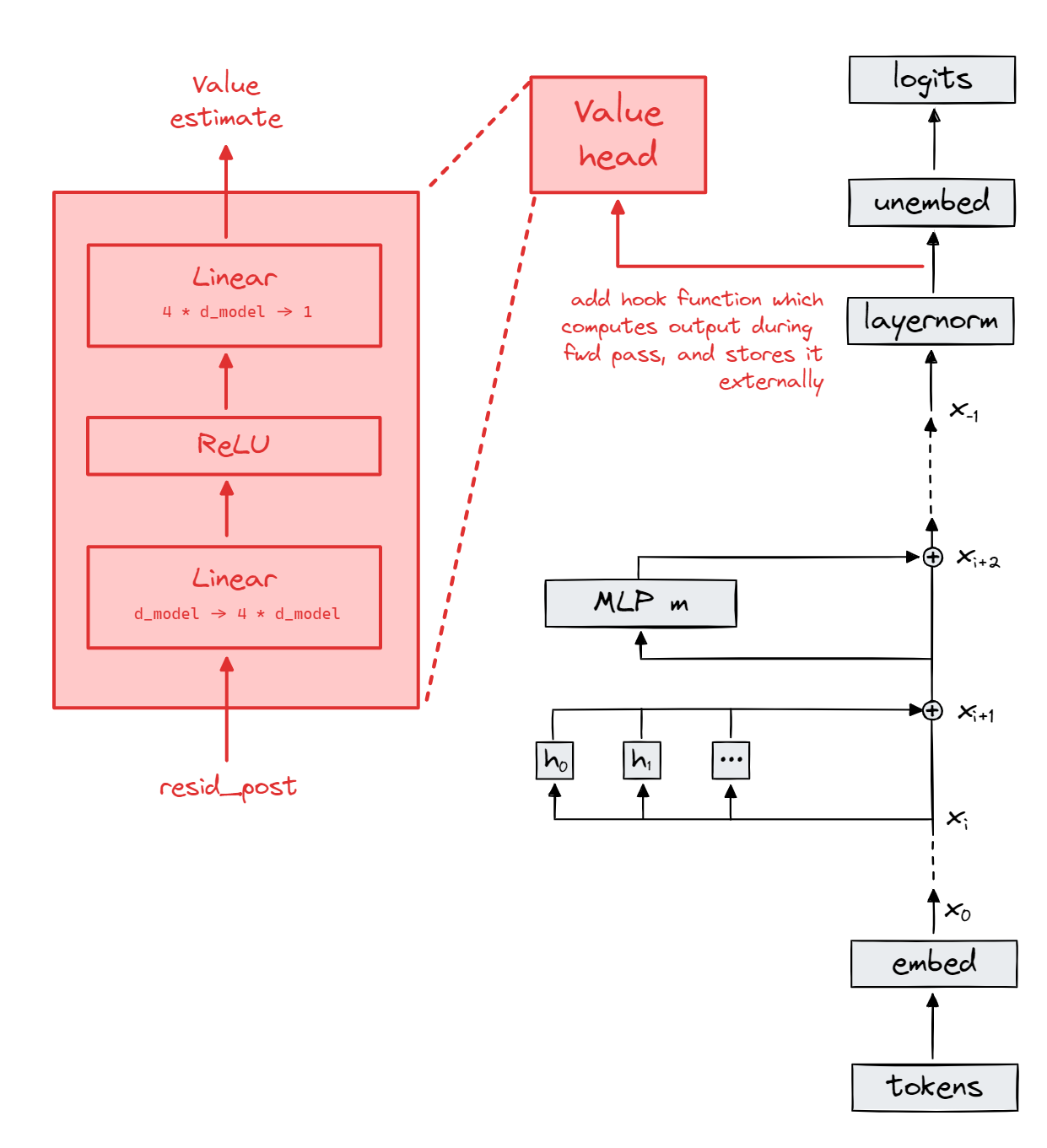
This leads to the idea of a value head. A value head is basically just a simple classifier model which we stick to one of the policy network's internal activations. You can think of this as a kind of feature extraction. When it comes to transformer models, we usually attach our value head to the value of the residual stream at the very last layer, after layernorm but before unembedding. Recall the key idea of residual stream as output accumulation - by the very last layer, it contains the most context about the overall sequence.*
*Technically this might not always be true, since there is some evidence that components of a transformer erase information in order to write different information to the residual stream. However, in practice we usually find that the residual stream at the last layer is the most useful for downstream tasks.
How do we implement this? Before you read further down, try to think about how you might implement this yourself, i.e. how you could extend the functionality of your HookedTransformer model by adding a value head, without completely rewriting the HookedTransformer architecture.
Hint
Think about using hook functions.
Answer
One method would be to directly edit the model by replacing its modules with different ones. But this is a bit awkward, because we have to also change modules which are downstream of the value head to make sure that they're only taking the residual stream as input (not the value head's output), etc.
A different method, which is what we'll be using in these exercises, is to use hook functions. We can attach a hook function to the residual stream at the final layer, and have it apply our value head to the residual stream values & store the output externally. Then we can use model.run_with_hooks to get our logits like normal, and fetch our value estimate from the external storage object.
We're used to using hook functions during inference mode to perform causal interventions or compute statistical functions of our activations, but they can also be used during training mode to perform computations which are part of the autograd's computational graph.
Exercise - implement HookedTransformerWithValueHead
Here is a diagram of your implementation.
-
Define the class method
.from_pretrainedto call the parent class's.from_pretrainedmethod, and then afterwards define the value headself.value_head. -
We have an extra argument
use_value_head. If it is false, just letmodel.value_head = None. We do this so we can reuse this class for the GRPO section. -
Rewrite the
forwardmethod so that it outputs both the logits from a forward pass and the output of the value head.
The easiest and most direct way to get the output of the value head would be to add a hook to the residual stream before the unembedding matrix, which computes the output of the value head and stores it externally (or as a class attribute). You can review the material from section 1.2 if you don't remember how to use hooks, and you can refer to the diagram on the reference page (find it on the left hand sidebar) for how to get the correct hook name.
Why do we need to add the hook after the layernorm?
The answer is that the residual stream can often grow in magnitude over time. Our rewards will be normalized (see later exercise), and so we want to make sure the outputs of our value head (which are estimates of the reward) also start off normalized.
class HookedTransformerWithValueHead(HookedTransformer):
"""
Defines a GPT model with a value head (the latter taking the last hidden state as input, post-layernorm).
The value head is a simple MLP with one hidden layer, and scalar output:
Linear(d_model -> 4*d_model)
ReLU
Linear(4*d_model -> 1)
All linear layers have biases.
"""
value_head: nn.Sequential
value_head_output: Float[Tensor, "batch seq"]
value_head_hook: list[tuple[str, Callable]]
@classmethod
def from_pretrained(cls, *args, use_value_head=True, **kwargs):
model = super(HookedTransformerWithValueHead, cls).from_pretrained(*args, **kwargs)
model.value_head_hook = ("ln_final.hook_normalized", model.run_value_head)
raise NotImplementedError()
@property
def fwd_hooks(self):
return [self.value_head_hook]
def get_base_model_trainable_params(self):
return (p for name, p in self.named_parameters() if "value_head" not in name)
def get_value_head_params(self):
return self.value_head.parameters()
def run_value_head(self, resid_post: Float[Tensor, "batch seq d_model"], hook: HookPoint):
raise NotImplementedError()
def forward_with_value_head(
self,
input_ids: Int[Tensor, "batch seq"],
**kwargs,
) -> tuple[Float[Tensor, "batch seq d_vocab"], Int[Tensor, "batch seq"]]:
raise NotImplementedError()
# Define a reference model (we'll use this during RLHF)
model = HookedTransformerWithValueHead.from_pretrained("pythia-14m", use_value_head=True).to(device)
tests.test_transformer_with_value_head(model)
Solution
We do this by storing the value head output as a property before returning it.
class HookedTransformerWithValueHead(HookedTransformer):
"""
Defines a GPT model with a value head (the latter taking the last hidden state as input, post-layernorm).
The value head is a simple MLP with one hidden layer, and scalar output:
Linear(d_model -> 4*d_model)
ReLU
Linear(4*d_model -> 1)
All linear layers have biases.
"""
value_head: nn.Sequential
value_head_output: Float[Tensor, "batch seq"]
value_head_hook: list[tuple[str, Callable]]
@classmethod
def from_pretrained(cls, *args, use_value_head=True, **kwargs):
model = super(HookedTransformerWithValueHead, cls).from_pretrained(*args, **kwargs)
model.value_head_hook = ("ln_final.hook_normalized", model.run_value_head)
if use_value_head:
model.value_head = nn.Sequential(
nn.Linear(model.cfg.d_model, 4 * model.cfg.d_model), nn.ReLU(), nn.Linear(4 * model.cfg.d_model, 1)
)
else:
model.value_head = None
return model
@property
def fwd_hooks(self):
return [self.value_head_hook]
def get_base_model_trainable_params(self):
return (p for name, p in self.named_parameters() if "value_head" not in name)
def get_value_head_params(self):
return self.value_head.parameters()
def run_value_head(self, resid_post: Float[Tensor, "batch seq d_model"], hook: HookPoint):
self.value_head_output = self.value_head(resid_post).squeeze(-1)
def forward_with_value_head(
self,
input_ids: Int[Tensor, "batch seq"],
**kwargs,
) -> tuple[Float[Tensor, "batch seq d_vocab"], Int[Tensor, "batch seq"]]:
self.value_head_output = None
logits = self.run_with_hooks(
input_ids,
return_type="logits",
fwd_hooks=self.fwd_hooks,
)
return logits, self.value_head_output
# Define a reference model (we'll use this during RLHF)
model = HookedTransformerWithValueHead.from_pretrained("pythia-14m", use_value_head=True).to(device)
tests.test_transformer_with_value_head(model)
Sampling from a transformer
If you didn't go through the sampling exercises during the first day of last week, you might want to go back to them and work through the first few of them (this is not essential). Otherwise, here's a quick refresher:
Sampling methods
- The simplest form of sampling is greedy sampling, where we autoregressively generate text by always choosing the most likely token at each step (i.e. argmaxing over logits), appending this to our sequence, and continuing.
- Most other forms of sampling are non-deterministic, i.e. they involve randomness. The most basic form of random sampling is choosing the next token according to the model's logit distribution.
- Other common refinements of this basic method are:
- Top-k sampling, where we only consider the top-k most likely tokens at each step, and choose from these according to the model's logit distribution.
- Top-p sampling (also called nucleus sampling), where we only consider the most likely tokens that have cumulative probability at least $p$ at each step, and choose from these according to the model's logit distribution.
We've provided the model sampling code for you below, because there are a few non-obvious things to consider that are specific to our current situation. Make sure you completely understand this function before moving on to the next section.
We'll highlight a few things about this function:
-
generateis the standard method to autoregressively generate text. This works for TransformerLens slightly differently than for HuggingFace models (TransformerLens isn't primarily designed for text generation). In particular (at time of writing), it doesn't have features to efficiently generate multiple outputs for a single completion by using key-value caching. So rather than passing an argument intogeneratetelling the model to generatebatch_sizeoutputs, we've instead just repeatedinput_idsmultiple times across the batch dimension. This may sound a bit wasteful since we're repeating computation on the input sequence, but it's not a big problem because the input sequences we'll be using are usually very short. We would only expect to see a significant slowdown when the prompt was very long, and the generations very short (recall that since the prompt is run in parallel, but autoregressive sampling is sequential, most of the wall-time is spent waiting for the model to generate the next token). -
We've used
stop_at_eos=False, to make sure that the model generates the fullgen_lengthtokens rather than stopping early.
@t.no_grad()
def get_samples(
model: HookedTransformer,
prompt: str,
batch_size: int,
gen_len: int = 15,
temperature: float = 0.8,
top_k: int = 15,
prepend_bos: bool = True,
**kwargs,
) -> tuple[Int[Tensor, "batch seq"], list[str]]:
"""
Generates samples from the model, which will be fed into the reward model and evaluated.
Inputs:
model: the transformer to generate samples from
prompt: the initial prompt fed into the model
batch_size: the number of samples to generate
gen_len: the length of the generated samples (i.e. the number of *new* tokens to generate)
temperature: the temp of the sampling distribution (higher means more random completions)
top_k: the topk parameter of sampling (higher means a wider variety of possible completions)
Returns:
sample_ids: the token ids of the generated samples (including initial prompt)
samples: the generated samples (including initial prompt)
"""
# Convert our prompt into tokens
input_ids = model.to_tokens(prompt, prepend_bos=prepend_bos)
input_ids = einops.repeat(input_ids, "1 seq -> batch seq", batch=batch_size)
# Generate samples
output_ids = model.generate(
input_ids,
max_new_tokens=gen_len,
stop_at_eos=False,
temperature=temperature,
top_k=top_k,
**kwargs,
)
samples = model.to_string(output_ids)
return output_ids.clone(), samples
Here's some example use of this function. You may wish to set use_past_kv_cache=False (default True) to see how much of a difference it makes, and verbose=True if you want a progress bar while generating tokens.
model = HookedTransformerWithValueHead.from_pretrained(BASE_MODEL).to(device)
sample_ids, samples = get_samples(
model,
prompt="So long, and thanks for all the",
batch_size=5,
gen_len=15,
temperature=0.8,
top_k=15,
prepend_bos=False,
verbose=True,
use_past_kv_cache=True,
)
table = Table("Token IDs", "Samples", title="Demo of `sample` function", show_lines=True)
for ids, sample in zip(sample_ids, samples):
table.add_row(str(ids.tolist()), repr(sample))
rprint(table)
Demo of `sample` function ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Token IDs ┃ Samples ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ [2396, 890, 11, 290, 5176, 329, 477, 262, 1104, 12930, │ 'So long, and thanks for all the support Ian, you made │ │ 11, 345, 925, 502, 1254, 6613, 286, 644, 314, 466, 13, │ me feel proud of what I do.\n\n' │ │ 198, 198] │ │ ├────────────────────────────────────────────────────────┼────────────────────────────────────────────────────────┤ │ [2396, 890, 11, 290, 5176, 329, 477, 262, 1842, 13, │ "So long, and thanks for all the │ │ 198, 198, 93, 7447, 24408, 50256, 19156, 50256, 51, │ love.\n\n~Stefan<|endoftext|>Robert<|endoftext|>T<|en… │ │ 50256, 2061, 338, 3931] │ summer" │ ├────────────────────────────────────────────────────────┼────────────────────────────────────────────────────────┤ │ [2396, 890, 11, 290, 5176, 329, 477, 262, 1842, 11, │ 'So long, and thanks for all the love, Cara\n\n" I │ │ 1879, 64, 198, 198, 1, 314, 1464, 1441, 534, 869, 11, │ always return your call, Cara' │ │ 1879, 64] │ │ ├────────────────────────────────────────────────────────┼────────────────────────────────────────────────────────┤ │ [2396, 890, 11, 290, 5176, 329, 477, 262, 1104, 0, │ 'So long, and thanks for all the │ │ 50256, 464, 6203, 4868, 329, 428, 8414, 373, 4481, │ support!<|endoftext|>The decklist for this contest was │ │ 416, 262, 1708, 1048] │ posted by the following person' │ ├────────────────────────────────────────────────────────┼────────────────────────────────────────────────────────┤ │ [2396, 890, 11, 290, 5176, 329, 477, 262, 1104, 290, │ 'So long, and thanks for all the support and │ │ 24054, 13, 314, 423, 587, 28368, 286, 530, 1110, 814, │ anticipation. I have been dreaming of one day │ │ 1586, 422, 262] │ differing from the' │ └────────────────────────────────────────────────────────┴────────────────────────────────────────────────────────┘
The **kwargs argument is passed along to generate, so as a reference you may wish to check the docstring, or the source code of the generate method. As a reminder, at time of writing we are using version 2.11.0 of TransformerLens in case you're digging deeper into the source code.
generate docstring
@torch.inference_mode()
def generate(
self,
input: Union[str, Float[torch.Tensor, "batch pos"]] = "",
max_new_tokens: int = 10,
stop_at_eos: bool = True,
eos_token_id: int | None = None,
do_sample: bool = True,
top_k: int | None = None,
top_p: float | None = None,
temperature: float = 1.0,
freq_penalty: float = 0.0,
use_past_kv_cache: bool = True,
prepend_bos: bool | None = USE_DEFAULT_VALUE,
padding_side: Literal["left", "right"] | None = USE_DEFAULT_VALUE,
return_type: str | None = "input",
verbose: bool = True,
) -> Union[Int[torch.Tensor, "batch pos_plus_new_tokens"], str]:
"""Sample Tokens from the Model.
Sample tokens from the model until the model outputs eos_token or max_new_tokens is reached.
To avoid fiddling with ragged tensors, if we input a batch of text and some sequences finish
(by producing an EOT token), we keep running the model on the entire batch, but throw away
the output for a finished sequence and just keep adding EOTs to pad.
This supports entering a single string, but not a list of strings - if the strings don't
tokenize to exactly the same length, this gets messy. If that functionality is needed,
convert them to a batch of tokens and input that instead.
Args:
input (Union[str, Int[torch.Tensor, "batch pos"])]): Either a batch of tokens ([batch,
pos]) or a text string (this will be converted to a batch of tokens with batch size
1).
max_new_tokens (int): Maximum number of tokens to generate.
stop_at_eos (bool): If True, stop generating tokens when the model outputs eos_token.
eos_token_id (int | Sequence[int] | None): The token ID to use for end
of sentence. If None, use the tokenizer's eos_token_id - required if using
stop_at_eos. It's also possible to provide a list of token IDs (not just the
eos_token_id), in which case the generation will stop when any of them are output
(useful e.g. for stable_lm).
do_sample (bool): If True, sample from the model's output distribution. Otherwise, use
greedy search (take the max logit each time).
top_k (int | None): Number of tokens to sample from. If None, sample from all tokens.
top_p (float | None): Probability mass to sample from. If 1.0, sample from all tokens. If <1.0,
we take the top tokens with cumulative probability >= top_p.
temperature (float): Temperature for sampling. Higher values will make the model more
random (limit of temp -> 0 is just taking the top token, limit of temp -> inf is
sampling from a uniform distribution).
freq_penalty (float): Frequency penalty for sampling - how much to penalise previous
tokens. Higher values will make the model more random.
use_past_kv_cache (bool): If True, create and use cache to speed up generation.
prepend_bos (bool, optional): Overrides self.cfg.default_prepend_bos. Whether to prepend
the BOS token to the input (applicable when input is a string). Defaults to None,
implying usage of self.cfg.default_prepend_bos (default is True unless specified
otherwise). Pass True or False to override the default.
padding_side (Literal["left", "right"] | None, optional): Overrides
self.tokenizer.padding_side. Specifies which side to pad when tokenizing multiple
strings of different lengths.
return_type (str | None): The type of the output to return - either a string (str),
a tensor of tokens (tensor) or whatever the format of the input was (input).
verbose (bool): If True, show tqdm progress bars for generation.
Returns:
outputs (torch.Tensor): [batch, pos + max_new_tokens], generated sequence of new tokens
(by default returns same type as input).
"""
Exercise - implement reward_fn_char_count
We'll start with a very basic reward function: counting the total number of periods in the sequence.
An interesting thing to note about this reward function - it counts over all characters, but the episode length is defined in terms of tokens. This means that theoretically our model could reward hack by outputting tokens with more than one . character. This particular model's vocabulary happens to include the token '.' * 64, (token 23193) so rewards would be through the roof if this was ever generated! However, remember that RL is about performing actions, getting feedback on those actions, and using that feedback to influence your policy. The token '.' * 64 is so unlikely to ever be generated that it'll probably never be positively reinforced, and we avoid this problem.
If we were worried about this, we could instead have the reward be the number of tokens that contain at least one ., or normalize over character count, or something similar. For now, this is jsut an easy reward function that we can use to quickly verify that our RLHF trainer is working.
def reward_fn_char_count(generated_sample: list[str], char: str = ".") -> Float[Tensor, " batch"]:
"""
Reward function (counting number of instances of a particular character), evaluated on the
generated samples. The return type should be a tensor of floats.
"""
raise NotImplementedError()
# Test your reward function
A = "This is a test."
B = "......"
C = "Whatever"
t.testing.assert_close(reward_fn_char_count([A]), t.tensor([1.0], device=device))
t.testing.assert_close(reward_fn_char_count([A, B, C]), t.tensor([1.0, 6.0, 0.0], device=device))
t.testing.assert_close(reward_fn_char_count([A], " "), t.tensor([3.0], device=device))
print("All tests for `reward_fn_char_count` passed!")
Solution
def reward_fn_char_count(generated_sample: list[str], char: str = ".") -> Float[Tensor, " batch"]:
"""
Reward function (counting number of instances of a particular character), evaluated on the
generated samples. The return type should be a tensor of floats.
"""
return t.tensor([item.count(char) for item in generated_sample], device=device, dtype=t.float)
Exercise - brainstorm your reward function
Take 5 minutes (on your own or with a partner) to brainstorm how the model might be able to maximize the output of periods in ways which don't produce incoherent output (e.g. collapsing into only outputting periods). Remember we have a KL penalty with the reference model, meaning the model is penalized for producing outputs which would be very unlikely under the original model. What ideas can you come up with? When you train your model and observe the output, you should come back here and see how many of the period-maximizing behaviours you predicted actually occur.
This exercise is a great way to start thinking about the effects of different reward functions - although it's only a toy example, it still illustrates the important alignment concept that the behaviour induced by certain reward functions might not always be what you expect!
Spoiler - which behaviours will your model pick up?
The strategies adopted by the model very a lot depending on the prefix string, also thanks to mode collapse it will often find one of these behaviours and entirely ignore the others.
Some common strategies include:
- Shorter sentences
- Repeating
U.S.orU.S.A.(using the prefix prompt"There is", this seems to be by far the most common strategy) - Library versions e.g.
Python 2.7.12orthe 2.6.0.2 release - Names with initials e.g.
C. S. Lewisor titles e.g.Dr.andPhD. - Abbreviations e.g.
Data-R.A.R. seriesor"L.A. Times" - Decimals in numbers e.g.
9.5cm x 7.5 cm - Ellipses e.g.
the man . . . the woman . . .
Exercise - implement normalize_reward
Following advice from Ziegler el al. (2019), it's important to normalize the reward function over each batch (i.e. subtract mean and divide by std dev). We've been able to get away with not doing this so far because our reward functions were usually nicely bounded, e.g. the reward was always zero or one in cartpole (and even in our reward shaping it was still in the zero-one range). But if we're working with reward functions that could be much higher variance such as the number of periods in a generated sequence, then we should normalize.
Note - we're not super strict about this function; the denominator being std + eps or (var + eps).sqrt() are both fine.
def normalize_reward(reward: Float[Tensor, " batch"], eps=1e-5) -> Float[Tensor, " batch"]:
"""
Normalizes the reward function values over the batch of sequences.
"""
raise NotImplementedError()
tests.test_normalize_reward(normalize_reward)
Solution
def normalize_reward(reward: Float[Tensor, " batch"], eps=1e-5) -> Float[Tensor, " batch"]:
"""
Normalizes the reward function values over the batch of sequences.
"""
return (reward - reward.mean()) / (reward.std() + eps)
Exercise - implement get_advantages
As we discussed earlier, your advantage function doesn't need to use GAE like yesterday. Instead, we'll base our estimates on the simple formula:
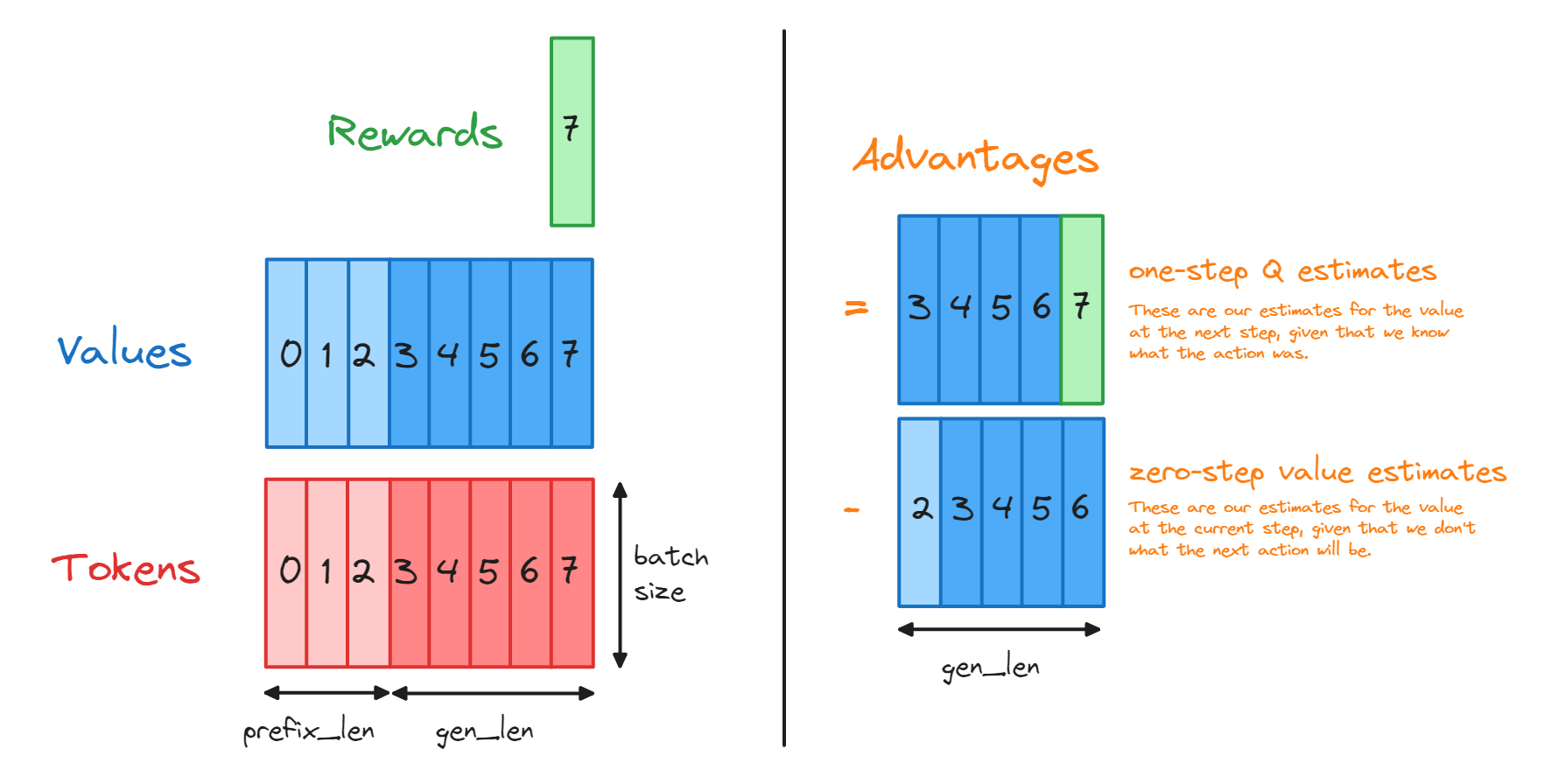
In place of $Q(s_t, a_t)$ we'll use the one-step Q estimates, i.e. our value function estimates after taking action $a_t$ at step $s_t$, meaning we're at new state $s_{t+1} = [s_t \; a_t]$. If $t < T$ (i.e. we're before the final sequence position) then the one-step Q estimates just equal the value function estimates $V(s_{t+1})$, but if $t=T$ then we can just use the known reward $r_t$ for the whole sequence (e.g. in our case that's the number of periods in the generated sequence).
The diagram below should help explain things. Note that the output should have shape [minibatch_size, gen_length] where gen_length is defined as seq_len - prefix_len i.e. the number of tokens our model generated. See the diagram below to help illustrate things, and make sure you slice your tensors carefully to match the diagram!
@t.no_grad()
def compute_advantages(
values: Float[Tensor, " minibatch_size seq_len"],
rewards: Float[Tensor, " minibatch_size"],
prefix_len: int,
) -> Float[Tensor, " minibatch_size gen_len"]:
"""
Computes the advantages for the PPO loss function, i.e. A_pi(s, a) = Q_pi(s, a) - V_pi(s).
In this formula we replace Q(s, a) with the 1-step Q estimates, and V(s) with the 0-step value estimates.
Inputs:
values:
the value estimates for each token in the generated sequence
rewards:
the rewards for the entire generated sequence
prefix_len:
the length of the prefix (i.e. the length of the initial prompt)
Returns:
advantages:
the advantages for each token in the generated sequence (not the entire sequence)
"""
raise NotImplementedError()
tests.test_compute_advantages(compute_advantages)
Solution
@t.no_grad()
def compute_advantages(
values: Float[Tensor, " minibatch_size seq_len"],
rewards: Float[Tensor, " minibatch_size"],
prefix_len: int,
) -> Float[Tensor, " minibatch_size gen_len"]:
"""
Computes the advantages for the PPO loss function, i.e. A_pi(s, a) = Q_pi(s, a) - V_pi(s).
In this formula we replace Q(s, a) with the 1-step Q estimates, and V(s) with the 0-step value estimates.
Inputs:
values:
the value estimates for each token in the generated sequence
rewards:
the rewards for the entire generated sequence
prefix_len:
the length of the prefix (i.e. the length of the initial prompt)
Returns:
advantages:
the advantages for each token in the generated sequence (not the entire sequence)
"""
# (see diagram) stack values [3, 4, 5, 6] and rewards [7,] to get the first term in our calculation of advantages
one_step_q_est = t.cat([values[:, prefix_len:-1], rewards[:, None]], dim=-1)
# (see diagram) slice values [2, 3, 4, 5, 6] to get our zero-step value estimates
zero_step_value_est = values[:, prefix_len - 1 : -1]
advantages = one_step_q_est - zero_step_value_est
return advantages
Memory
We've given you an implementation of the ReplayMemory and ReplayMinibatch classes.
Some notes on how ReplayMinibatch differs from the PPO implementation, mostly in ways which make it strictly simpler:
- We don't need to store
actionsany more, because the actions (tokens generated) are in contained within the sequences themselves. - We don't need to store
donesany more, because all our sequences last for exactlygen_lengthsteps. - We need to store
ref_logits, which are used to compute the KL penalty with respect to our reference model.
Some notes on how ReplayMemory differs from the PPO implementation, again mostly making it simpler:
- We don't have multiple environments to flatten over, which cuts down a lot of our previous boilerplate code.
- We won't use
addto add experience data one by one, intead we'll add it all at once. - Many of the tensors below have shape
(batch_size, gen_len)not(batch_size, seq_len), because we only care about their values for the generated tokens, not the prefix tokens (only the generated tokens correspond to actual actions our model took).
A note on returns, and how this relates to DQN (optional)
Note that because we're using simple 1-step advantage estimation rather than GAE, our returns are just equivalent to the next-step estimates of our value function (except for returns[:, -1] which equals our end-of-sequence rewards).
Recall from our discussion in PPO yesterday that the returns are used in the value function loss which plays a similar role to the DQN loss (of bringing the value estimates in line with the next-step value estimates). This parallel between the DQN loss and value function loss is even clearer here:
- DQN loss was the squared difference between current Q-value $Q_\theta(s_t, a_t)$ and the time-discounted next step Q-values for the target network $\theta_\text{target}$, the role was to improve $Q_\theta$ estimates
- Here, the value function loss reduces to the squared difference between the current value estimate $V_\theta(s_t)$ and the next-step value estimate $V_{\theta_\text{old}}(s_{t+1})$ computed during rollout, the role is to improve $V_\theta$ estimates
Obviously the formulas look different here becaause we have no discount ($\gamma = 1$) and we also have no rewards except at the final step ($r_t = 0 \; \forall t < T$), but the idea is fundamentally the same.
@dataclass
class ReplayMinibatch:
"""
Samples from the replay memory.
"""
sample_ids: Float[Tensor, " minibatch_size seq_len"]
logprobs: Float[Tensor, " minibatch_size gen_len"]
advantages: Float[Tensor, " minibatch_size gen_len"]
returns: Float[Tensor, " minibatch_size gen_len"]
ref_logits: Float[Tensor, " minibatch_size seq_len d_vocab"]
class ReplayMemory:
def __init__(
self,
args: RLHFArgs,
sample_ids: Float[Tensor, " batch_size seq_len"],
logprobs: Float[Tensor, " batch_size gen_len"],
advantages: Float[Tensor, " batch_size gen_len"],
values: Float[Tensor, " batch_size seq_len"],
ref_logits: Float[Tensor, " batch_size seq_len d_vocab"],
):
"""
Initializes the replay memory, with all the data generated from the rollout phase at once.
The advantages are (batch_size, gen_len) because we only compute advantages for the generated
tokens. The other tensors, except logprobs, uses seq_len instead of gen_len because they are
computed for all tokens.
"""
assert ref_logits.ndim == 3
assert ref_logits.shape[0] == args.batch_size
assert sample_ids.shape == values.shape == ref_logits.shape[:2]
assert advantages.shape == logprobs.shape == (args.batch_size, args.gen_len)
self.args = args
self.sample_ids = sample_ids
self.logprobs = logprobs
self.advantages = advantages
self.values = values
self.ref_logits = ref_logits
def get_minibatches(self) -> list[ReplayMinibatch]:
"""
Generates a list of minibatches by randomly sampling from the replay memory. Each sequence
appears exactly `batches_per_learning_phase` times in total.
"""
minibatches = []
returns = self.advantages + self.values[:, -self.args.gen_len - 1 : -1]
for _ in range(self.args.batches_per_learning_phase):
for indices in t.randperm(self.args.batch_size).reshape(self.args.num_minibatches, -1):
minibatches.append(
ReplayMinibatch(
sample_ids=self.sample_ids[indices],
logprobs=self.logprobs[indices],
advantages=self.advantages[indices],
returns=returns[indices],
ref_logits=self.ref_logits[indices],
)
)
return minibatches
RLHF Agent?
If we were matching our implementation to our PPO implementation yesterday, this is where we'd define an RLHFAgent class. This class would have the role of:
- Managing interactions between the agent and the environment
- Sequentially taking steps in the environment and storing these steps as experience tuples in
ReplayMemory
However, we're not going to do this here because it's not a useful abstraction in our case - there's no clear separation between our agent and our environment like there was yesterday. Instead, most of the extra logic in play_step (i.e. generating tokens and storing the associated experiences in replay memory) will be handled later in the rollout_phase method of your RLHFTrainer class.
Objective function
Exercise - implement calc_kl_penalty
Now, you'll implement the KL penalty function. As discussed, the purpose of this function is to make sure your new model doesn't diverge too much from the old model. We'll be using the KL divergence between the old and new models' logit distributions.
The formula for KL divergence of two distributions, $D_{\text{KL}}(P || Q)$, is $\sum_i P_i \log (P_i / Q_i)$. Recall that we want our new logits to be $P$ and reference logits to be $Q$ (because this penalizes our new model for generating outputs which would be very unlikely under the original reference model).
A few other tips / notes about this implementation:
- We only pass
logitsandref_logitsfor the generated tokens- This is because we don't care about the model's logits for prefix tokens, since it's not in control of them
- You should pay attention to numerical stability when calculating KL div
- This means for example you shouldn't take
softmaxto get probabilities thenlogto get logits, since taking the log of very small numbers is unstable - You should instead use something like
log_softmaxto get logprobs thenexpto get probabilities, which works sincelog_softmaxis stable (it subtracts a constant from all the logits so they're not all extremely negative) andexpof a negative number is stable
- This means for example you shouldn't take
- You should sum over the
d_vocabdimension, but take the mean over batch & pos dimensions, since each token represents a separate observation and action.
def calc_kl_penalty(
logits: Float[Tensor, "minibatch_size gen_len d_vocab"],
ref_logits: Float[Tensor, "minibatch_size gen_len d_vocab"],
kl_coef: float,
gen_len: int,
) -> Float[Tensor, ""]:
"""
Computes the KL divergence between the logits and the reference logits, scaled
by the penalty function. This is used to stop the learned policy from diverging
too much from the original reference model's policy.
Args:
logits:
The logits for all generated tokens (under the new model).
ref_logits:
The logits for the generated tokens (under the reference model).
kl_coef:
The coefficient of the KL penalty.
gen_len:
the number of generated tokens (i.e. the number of tokens we want to compute kl penalty for)
Output:
The KL divergence between the logits and the reference logits, scaled by kl_coef.
"""
assert logits.shape[1] == ref_logits.shape[1] == gen_len, (
"Should pass in logits & ref_logits for generated tokens only, i.e. [:, -gen_len-1: -1]"
)
raise NotImplementedError()
tests.test_calc_kl_penalty(calc_kl_penalty)
tests.test_calc_kl_penalty_stability(calc_kl_penalty)
Solution
def calc_kl_penalty(
logits: Float[Tensor, "minibatch_size gen_len d_vocab"],
ref_logits: Float[Tensor, "minibatch_size gen_len d_vocab"],
kl_coef: float,
gen_len: int,
) -> Float[Tensor, ""]:
"""
Computes the KL divergence between the logits and the reference logits, scaled
by the penalty function. This is used to stop the learned policy from diverging
too much from the original reference model's policy.
Args:
logits:
The logits for all generated tokens (under the new model).
ref_logits:
The logits for the generated tokens (under the reference model).
kl_coef:
The coefficient of the KL penalty.
gen_len:
the number of generated tokens (i.e. the number of tokens we want to compute kl penalty for)
Output:
The KL divergence between the logits and the reference logits, scaled by kl_coef.
"""
assert logits.shape[1] == ref_logits.shape[1] == gen_len, (
"Should pass in logits & ref_logits for generated tokens only, i.e. [:, -gen_len-1: -1]"
)
ref_logprobs = ref_logits.log_softmax(-1)
logprobs = logits.log_softmax(-1)
probs = logprobs.exp()
kl_div = (probs * (logprobs - ref_logprobs)).sum(-1)
return kl_coef * kl_div.mean()
Exercise - (re)implement compute_entropy_bonus
Next, we'll implement the entropy bonus function again. Rather than working with probs.entropy() like yesterday, we'll need to compute entropy directly from the logits, and take the mean over batch and sequence position dimensions.
The formula for entropy of a distribution $P$ is $- \sum_i P_i \log P_i$. You'll need to take the same numerical stability precautions as the previous exercise.
def calc_entropy_bonus(
logits: Float[Tensor, "minibatch_size gen_len d_vocab"], ent_coef: float, gen_len: int
) -> Float[Tensor, ""]:
"""
Return the entropy bonus term, suitable for gradient ascent.
Args:
logits:
the logits of the tokens generated by the model before each generated token
ent_coef:
the coefficient for the entropy loss, which weights its contribution to the overall
objective function.
gen_len:
the number of generated tokens (i.e. the number of tokens we want to compute the entropy
bonus for).
"""
assert logits.shape[1] == gen_len, "Should pass in logits *before* all generated tokens, i.e. [:, -gen_len-1: -1]"
raise NotImplementedError()
tests.test_calc_entropy_bonus(calc_entropy_bonus)
tests.test_calc_entropy_bonus_stability(calc_entropy_bonus)
Solution
def calc_entropy_bonus(
logits: Float[Tensor, "minibatch_size gen_len d_vocab"], ent_coef: float, gen_len: int
) -> Float[Tensor, ""]:
"""
Return the entropy bonus term, suitable for gradient ascent.
Args:
logits:
the logits of the tokens generated by the model before each generated token
ent_coef:
the coefficient for the entropy loss, which weights its contribution to the overall
objective function.
gen_len:
the number of generated tokens (i.e. the number of tokens we want to compute the entropy
bonus for).
"""
assert logits.shape[1] == gen_len, "Should pass in logits *before* all generated tokens, i.e. [:, -gen_len-1: -1]"
logprobs = logits.log_softmax(dim=-1)
probs = logprobs.exp()
entropy = -(probs * logprobs).sum(dim=-1)
return ent_coef * entropy.mean()
Other objective function terms
Since the other two terms in our objective function (value function loss and clipped surrogate objective) are pretty much identical to yesterday's, we've provided them for you (taken from yesterday's solutions code). We've added some extra comments in the docstrings to highlight how they differ from yesterday's PPO implementation.
You should pay attention to the shapes of the inputs to these functions (in particular whether they're shape seq_len meaning they're for all tokens, or gen_len meaning they're only for tokens after the prefix), so that you use them correctly when you're writing the RLHFTrainer methods.
def calc_value_function_loss(
values: Float[Tensor, "minibatch_size gen_len"],
mb_returns: Float[Tensor, "minibatch_size gen_len"],
vf_coef: float,
gen_len: int,
) -> Float[Tensor, ""]:
"""Compute the value function portion of the loss function.
Note that for RLHF with advantages = TD residuals rather than GAE, this is equivalent to
penalizing the squared error between values[t] and mb_values[t+1]. This is essentially
equivalent to our TD loss expression for DQN, where we penalized the current network's Q values
and the next-step target network Q values. The role is the same in both cases: to improve the
accuracy (and reduce the variance) of our value function estimates.
values:
the value function predictions for the sampled minibatch, for all generated tokens (using
the updated critic network).
mb_returns:
the target for our updated critic network (computed as `advantages + values` from the old
network).
vf_coef:
the coefficient for the value loss, which weights its contribution to the overall loss.
Denoted by c_1 in the paper.
gen_len:
the number of generated tokens, used for shape checking
"""
assert values.shape[1] == gen_len, "Should pass in values before all generated tokens, i.e. [:, -gen_len-1: -1]"
assert mb_returns.shape[1] == gen_len, "Should pass in returns before all generated tokens only"
return 0.5 * vf_coef * (values - mb_returns).pow(2).mean()
def calc_clipped_surrogate_objective(
logprobs: Float[Tensor, "minibatch_size gen_len"],
mb_logprobs: Float[Tensor, "minibatch_size gen_len"],
mb_advantages: Float[Tensor, "minibatch_size gen_len"],
clip_coef: float,
gen_len: int,
eps: float = 1e-8,
) -> Float[Tensor, ""]:
"""Return the clipped surrogate objective, suitable for maximisation with gradient ascent.
Note that for RLHF, we only care about the logprobs for the generated tokens, i.e. after the
prefix. This is because we're fixing the prefix tokens and the model can't change its output for
them, so there's no point including these in our objective function.
logprobs:
the logprobs of the action taken by the agent, according to the new policy
mb_logprobs:
logprobs of the actions taken in the sampled minibatch (according to the old policy)
mb_advantages:
advantages calculated from the sampled minibatch
clip_coef:
amount of clipping, denoted by epsilon in Eq 7.
gen_len:
the number of generated tokens, used for shape checking
eps:
used to add to std dev of mb_advantages when normalizing (to avoid dividing by zero)
"""
assert logprobs.shape[1] == mb_logprobs.shape[1] == mb_advantages.shape[1] == gen_len, (
"Should pass in logprob/advantage data for generated tokens only, i.e. [:, -gen_len-1: -1]"
)
logits_diff = logprobs - mb_logprobs
r_theta = t.exp(logits_diff)
mb_advantages = normalize_reward(mb_advantages, eps)
non_clipped = r_theta * mb_advantages
clipped = t.clip(r_theta, 1 - clip_coef, 1 + clip_coef) * mb_advantages
return t.minimum(non_clipped, clipped).mean()
Exercise - implement get_logprobs
You'll notice that the functions above take logprobs of shape (minibatch_size, gen_len), i.e. the logprobs on correct tokens for all the tokens generated by the model. This is because we don't care about the logprobs the model assigns to the prefix tokens, since it's not in control of them. So you'll find it useful to implement the function get_logprobs below, which returns the logprobs for the correct tokens after the prefix. For example:
- If
prefix_len = 1then all the model's logprobs are predicting non-prefix tokens, so we returnlogprobs[:, :-1]indexed at the non-prefix correct next tokens i.e.tokens[:, 1:]. The return type has shape(batch, seq_len-1). - If
prefix_len = 2then we discard the very first logprob because it's predicting part of the prefix not new actions, so we returnlogprobs[:, 1:-1]indexed at the non-prefix correct next tokens i.e.tokens[:, 2:]. The return type has shape(batch, seq_len-2).
When prefix_len is None you should have the same behaviour as if prefix_len = 1, i.e. returning seq_len-1 correct logprobs.
You can implement this function using regular indexing, tools like torch.gather, or with the eindex library which should be included in your dependencies (see here for how to use this library).
def get_logprobs(
logits: Float[Tensor, "batch seq_len vocab"],
tokens: Int[Tensor, "batch seq_len"],
prefix_len: int | None = None,
) -> Float[Tensor, "batch gen_len"]:
"""
Returns correct logprobs for the given logits and tokens, for all the tokens after the prefix
tokens (which have length equal to `prefix_len`).
If prefix_len = None then we return shape (batch, seq_len-1).
If not, then we return shape (batch, seq_len-prefix_len) representing the predictions for all
toks after the prefix.
"""
raise NotImplementedError()
tests.test_get_logprobs(get_logprobs)
Solution
def get_logprobs(
logits: Float[Tensor, "batch seq_len vocab"],
tokens: Int[Tensor, "batch seq_len"],
prefix_len: int | None = None,
) -> Float[Tensor, "batch gen_len"]:
"""
Returns correct logprobs for the given logits and tokens, for all the tokens after the prefix
tokens (which have length equal to `prefix_len`).
If prefix_len = None then we return shape (batch, seq_len-1).
If not, then we return shape (batch, seq_len-prefix_len) representing the predictions for all
toks after the prefix.
"""
# Slice our tensors based on prefix_len
if prefix_len is not None:
logits = logits[:, prefix_len - 1 :]
tokens = tokens[:, prefix_len - 1 :]
# Get logprobs
logprobs = logits.log_softmax(-1)
# We want to get elements `logprobs[b, s, tokens[b, s+1]]`, we do this using eindex as follows:
correct_logprobs = eindex(logprobs, tokens, "b s [b s+1]")
return correct_logprobs
Optimizer & Scheduler
Exercise - implement get_optimizer
We need to be a bit careful when defining our optimizer. It makes no sense to have the same learning rate for our original model as we do for our value head. The value head was randomly initialized and has no idea what it's doing, but our model is pretrained and so it already has weights which have been trained to effectively extract features from text.
The syntax for using parameter groups in an optimizer is as follows:
parameter_groups = [
{"params": [param1, param2, ...], "lr": lr1},
{"params": [param3, param4, ...], "lr": lr2},
]
where params is a list (or iterable) of parameters, and lr is the learning rate for these parameters.
You should fill in the function get_optimizer below, so that the value head's parameters all have learning rate args.head_learning_rate and the base model's parameters all have learning rate args.base_learning_rate.
Remember that we're using maximize=True with our optimizer (since we're maximizing an objective function rather than minimizing a loss function). Also we're using the AdamW optimizer (our implementation doesn't include weight decay so we could in theory use Adam, but it's better to stick to AdamW just in case we want to add in weight decay later).
def get_optimizer(model: HookedTransformerWithValueHead, base_lr: float, head_lr: float) -> t.optim.Optimizer:
"""
Returns an AdamW optimizer for the model, with the correct learning rates for the base and head.
Make sure to use the HookedTransformerWithValueHead wrapper methods for getting the parameters.
"""
raise NotImplementedError()
tests.test_get_optimizer(get_optimizer, model)
Solution
def get_optimizer(model: HookedTransformerWithValueHead, base_lr: float, head_lr: float) -> t.optim.Optimizer:
"""
Returns an AdamW optimizer for the model, with the correct learning rates for the base and head.
Make sure to use the HookedTransformerWithValueHead wrapper methods for getting the parameters.
"""
return t.optim.AdamW(
[
{"params": model.get_base_model_trainable_params(), "lr": base_lr},
{"params": model.get_value_head_params(), "lr": head_lr},
],
maximize=True,
)
Scheduler
In PPO, we had you write a custom class for implementing learning rate scheduling. This was useful to help you engage with the low-level syntax of changing learning rates in Pytorch. However, PyTorch does provide a handy class for implementing custom learning rate scheduling:
optimizer = t.optim.Adam(...)
scheduler = t.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lr_lambda)
where lr_lambda is a function mapping the number of steps (i.e. number of times we've called scheduler.step()) to a float which gets multiplied by the base learning rate (i.e. 0.1 means we use 10% of the base LR). There are schedulers other than LambdaLR which have specific built-in behaviour (see documentation page), although this gives you the most flexibility.
Aside - why we use warmup
Warmup is a common strategy early in training, to make sure we don't get excessive updates early on. It seems to work pretty well empirically. Some possible reasons for this are:
- It helps avoid large updates when the Adam moving averages of first and second moments are not yet well calibrated.
- Early on in training, the gradients might be very large (especially for the value function) because the model's prediction is nowhere near where it needs to be. So an LR warmup is more useful early on, to help avoid massive steps.
We've given you the code you'll be using for returning a custom lr_lambda function with a linear warmup then linear decay. We've also provided code for you in the trainer class's init method below which creates your scheduler. All you need to do is make sure you're stepping it appropriately.
def get_optimizer_and_scheduler(args: RLHFArgs, model: HookedTransformerWithValueHead):
"""
Creates an AdamW optimizer and an LR scheduler that linearly warms up for `warmup_steps` steps,
and then linearly decays to `final_scale` over the remaining steps.
"""
def lr_lambda(step):
assert step <= args.total_phases, f"Step = {step} should be less than total_phases = {args.total_phases}."
if step < args.warmup_steps:
return step / args.warmup_steps
else:
return 1 - (1 - args.final_scale) * (step - args.warmup_steps) / (args.total_phases - args.warmup_steps)
optimizer = get_optimizer(model, args.base_lr, args.head_lr)
scheduler = t.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lr_lambda)
return optimizer, scheduler
If we want to log the learning rate, then we can use scheduler.get_last_lr() which gives you a list of learning rates for each parameter group (in our case, this would have length 2).
Training your model
We're now ready to put everything together! We've provided you with the template of a training loop which should be very similar to yesterday's.
Exercise - complete RLHFTrainer
The compute_rlhf_objective method should be very similar to yesterday's compute_ppo_objective method (i.e. it should compute the 3 terms in the PPO objective function and combine them into a single objective function which gets returned), although there are a few small differences:
- You also need to compute the KL penalty term with
calc_kl_penaltyand include it in the objective function - make sure you get the correct sign! - Rather than getting
logitsandvaluesfrom your actor and critic models, you get them both from theforwardmethod of yourTransformerWithValueHeadmodel.- Also, make sure you pass in the correct slices to your
calc_...objective functions (although they should flag if you've done this incorrectly via the assert statements at the start of these functions)
- Also, make sure you pass in the correct slices to your
The learning_phase method should be identical to yesterday's learning_phase method (i.e. it should generate minibatches via memory.get_minibatches() and then iterate through them, performing a step of gradient ascent on each). The only thing you need to adjust is the scheduler step - the way we've set it up, this should be done once per phase, not once per step (this is generally more common practice in ML; we step with the scheduler once per epoch).
A few tips / notes before you start:
- For faster feedback loops, don't use
wandbuntil you've stopped getting errors! - You can log text to Weights & Biases: just printing normal output should appear under the "Logs" section, but if you want to see it with the rest of your wandb charts then you can also use
wandb.Tableto log tables.
class RLHFTrainer:
model: HookedTransformerWithValueHead
ref_model: HookedTransformer
memory: ReplayMemory # we'll set this during rollout
def __init__(self, args: RLHFArgs):
t.manual_seed(args.seed)
self.args = args
self.run_name = f"{args.wandb_project_name}__seed{args.seed}__{time.strftime('%Y%m%d-%H%M%S')}"
self.model = HookedTransformerWithValueHead.from_pretrained(args.base_model).to(device).train()
self.ref_model = HookedTransformer.from_pretrained(args.base_model).to(device).eval()
self.optimizer, self.scheduler = get_optimizer_and_scheduler(self.args, self.model)
self.prefix_len = len(self.model.to_str_tokens(self.args.prefix, prepend_bos=self.args.prepend_bos))
def compute_rlhf_objective(self, minibatch: ReplayMinibatch):
"""
Computes the RLHF objective function to maximize, which equals the PPO objective function
modified by the KL penalty term.
Steps of this function are:
- Get logits & values for the samples in minibatch
- Get the logprobs of the minibatch actions taken
- Use this data to compute all 4 terms of the RLHF objective function, and return it
- Also optionally log stuff to Weights & Biases (and print some sample completions)
"""
gen_len_slice = slice(-self.args.gen_len - 1, -1)
raise NotImplementedError()
def rollout_phase(self) -> ReplayMemory:
"""
Performs a single rollout phase, returning a ReplayMemory object containing the data
generated during this phase. Note that all forward passes here should be done in inference
mode.
Steps of this function are:
- Generate samples from our model
- Get logits of those generated samples (from model & reference model)
- Get other data for memory (logprobs, normalized rewards, advantages)
- Return this data in a ReplayMemory object
"""
# Get our samples
sample_ids, samples = get_samples(
self.model,
prompt=self.args.prefix,
batch_size=self.args.batch_size,
gen_len=self.args.gen_len,
temperature=self.args.temperature,
top_k=self.args.top_k,
prepend_bos=self.args.prepend_bos,
verbose=False,
)
raise NotImplementedError()
def learning_phase(self, memory: ReplayMemory) -> float:
"""
Performs a learning step on `memory`. This involves the standard gradient descent steps
(i.e. zeroing gradient, computing objective function, doing backprop, stepping optimizer).
You should also remember the following:
- Clipping grad norm to the value given in `self.args.max_grad_norm`
- Incrementing `self.step` by 1 for each minibatch
- Stepping the scheduler (once per calling of this function)
Returns the average objective function value over the minibatches as a float for logging.
"""
raise NotImplementedError()
def train(self) -> None:
"""
Performs a full training run.
"""
self.step = 0
self.samples = []
if self.args.use_wandb:
wandb.init(
project=self.args.wandb_project_name,
entity=self.args.wandb_entity,
name=self.run_name,
config=self.args,
)
runner = tqdm(range(self.args.total_phases))
for self.phase in runner:
memory = self.rollout_phase()
loss = self.learning_phase(memory)
runner.set_description(f"Loss: {loss:.4f}")
if self.args.use_wandb:
wandb.finish()
Solution (simpler, no logging)
def compute_rlhf_objective(self, minibatch: ReplayMinibatch):
gen_len_slice = slice(-self.args.gen_len - 1, -1) # define this for convenience
# Get logits & values for our generated minibatch samples
logits, values = self.model(minibatch.sample_ids)
# Get logprobs for the the tokens generated (i.e. the logprobs of our actions)
logprobs = get_logprobs(logits, minibatch.sample_ids, self.prefix_len)
# Compute all terms of the loss function (including KL penalty)
clipped_surrogate_objective = calc_clipped_surrogate_objective(
logprobs, minibatch.logprobs, minibatch.advantages, self.args.clip_coef, self.args.gen_len
)
value_loss = calc_value_function_loss(
values[:, gen_len_slice], minibatch.returns, self.args.vf_coef, self.args.gen_len
)
entropy_bonus = calc_entropy_bonus(logits[:, gen_len_slice], self.args.ent_coef, self.args.gen_len)
kl_penalty = calc_kl_penalty(
logits[:, gen_len_slice], minibatch.ref_logits[:, gen_len_slice], self.args.kl_coef, self.args.gen_len
)
# Compute net objective function
ppo_objective_fn = clipped_surrogate_objective - value_loss + entropy_bonus
total_objective_function = ppo_objective_fn - kl_penalty
return total_objective_function
def rollout_phase(self) -> ReplayMemory:
# Get our samples
sample_ids, samples = get_samples(
self.model.base_model,
prompt=self.args.prefix,
batch_size=self.args.batch_size,
gen_len=self.args.gen_len,
temperature=self.args.temperature,
top_k=self.args.top_k,
prepend_bos=self.args.prepend_bos,
)
# Generate logits from our model & reference model
with t.inference_mode():
logits, values = self.model(sample_ids)
ref_logits = self.ref_model(sample_ids)
# Get the logprobs of the generated tokens
logprobs = get_logprobs(logits, sample_ids, self.prefix_len)
# Calculate & normalize rewards (note we don't normalize inplace, because we want to log unnormalized rewards)
rewards = self.args.reward_fn(samples)
rewards_mean = rewards.mean().item()
rewards_normed = normalize_reward(rewards) if self.args.normalize_reward else rewards
# Compute advantages
advantages = compute_advantages(values, rewards_normed, self.prefix_len)
return ReplayMemory(
args=self.args,
sample_ids=sample_ids,
logprobs=logprobs,
advantages=advantages,
values=values,
ref_logits=ref_logits,
)
def learning_phase(self, memory: ReplayMemory) -> None:
for minibatch in memory.get_minibatches():
self.optimizer.zero_grad()
total_objective_function = self.compute_rlhf_objective(minibatch)
total_objective_function.backward()
nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=self.args.max_grad_norm)
self.optimizer.step()
self.step += 1
self.scheduler.step()
Solution (full, with logging)
def compute_rlhf_objective(self, minibatch: ReplayMinibatch):
gen_len_slice = slice(-self.args.gen_len - 1, -1) # define this for convenience
# Get logits & values for our generated minibatch samples
logits, values = self.model(minibatch.sample_ids)
# Get logprobs for the the tokens generated (i.e. the logprobs of our actions)
logprobs = get_logprobs(logits, minibatch.sample_ids, self.prefix_len)
# Compute all terms of the loss function (including KL penalty)
clipped_surrogate_objective = calc_clipped_surrogate_objective(
logprobs, minibatch.logprobs, minibatch.advantages, self.args.clip_coef, self.args.gen_len
)
value_loss = calc_value_function_loss(
values[:, gen_len_slice], minibatch.returns, self.args.vf_coef, self.args.gen_len
)
entropy_bonus = calc_entropy_bonus(logits[:, gen_len_slice], self.args.ent_coef, self.args.gen_len)
kl_penalty = calc_kl_penalty(
logits[:, gen_len_slice], minibatch.ref_logits[:, gen_len_slice], self.args.kl_coef, self.args.gen_len
)
# Compute net objective function
ppo_objective_fn = clipped_surrogate_objective - value_loss + entropy_bonus
total_objective_function = ppo_objective_fn - kl_penalty
# Log stuff
with t.inference_mode():
logratio = logprobs - minibatch.logprobs
ratio = logratio.exp()
clipfracs = [((ratio - 1.0).abs() > self.args.clip_coef).float().mean().item()]
if self.args.use_wandb:
wandb.log(
dict(
total_steps=self.step,
lr=self.scheduler.get_last_lr()[0],
clipped_surrogate_objective=clipped_surrogate_objective.item(),
clipfrac=np.mean(clipfracs),
value_loss=value_loss.item(),
values=values.mean().item(),
entropy_bonus=entropy_bonus.item(),
kl_penalty=kl_penalty.item(),
),
step=self.step,
)
return total_objective_function
def rollout_phase(self) -> ReplayMemory:
# Get our samples
sample_ids, samples = get_samples(
self.model.base_model,
prompt=self.args.prefix,
batch_size=self.args.batch_size,
gen_len=self.args.gen_len,
temperature=self.args.temperature,
top_k=self.args.top_k,
prepend_bos=self.args.prepend_bos,
)
# Generate logits from our model & reference model
with t.inference_mode():
logits, values = self.model(sample_ids)
ref_logits = self.ref_model(sample_ids)
# Get the logprobs of the generated tokens
logprobs = get_logprobs(logits, sample_ids, self.prefix_len)
# Calculate & normalize rewards (note we don't normalize inplace, because we want to log unnormalized rewards)
rewards = self.args.reward_fn(samples)
rewards_mean = rewards.mean().item()
rewards_normed = normalize_reward(rewards) if self.args.normalize_reward else rewards
# Compute advantages
advantages = compute_advantages(values, rewards_normed, self.prefix_len)
# Log stuff, and print output in a readable way (you could easily just regular print here instead of rprint table)
if self.args.use_wandb:
wandb.log({"mean_reward": rewards_mean}, step=self.step)
n_log_samples = min(3, self.args.batch_size)
ref_logprobs = get_logprobs(ref_logits[:n_log_samples], sample_ids[:n_log_samples], self.prefix_len).sum(-1)
headers = ["Reward", "Ref logprobs", "Sample"]
table_data = [[str(int(r)), f"{lp:.2f}", repr(s)] for r, lp, s in zip(rewards.tolist(), ref_logprobs, samples)]
table = tabulate(table_data, headers, tablefmt="simple_grid", maxcolwidths=[None, None, 90])
print(f"Phase {self.phase+1:03}/{self.args.total_phases}, Mean reward: {rewards_mean:.4f}\n{table}\n")
return ReplayMemory(
args=self.args,
sample_ids=sample_ids,
logprobs=logprobs,
advantages=advantages,
values=values,
ref_logits=ref_logits,
)
def learning_phase(self, memory: ReplayMemory) -> None:
for minibatch in memory.get_minibatches():
self.optimizer.zero_grad()
total_objective_function = self.compute_rlhf_objective(minibatch)
total_objective_function.backward()
nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=self.args.max_grad_norm)
self.optimizer.step()
self.step += 1
self.scheduler.step()
Once you've implemented your trainer class, you can run the code below to train your model. We recommend you start with the test run below, using a KL coefficient of zero.
Question - with kl_coef=0.0, what results do you think you should reliably get?
With this KL coefficient, the model has no incentive to match the reference distribution, it will only try to maximize the reward. So once it's figured out that it can just output full stops all the time and totally abandon any kind of grammar or coherence, it will do this. By the end of 30 phases, the model should have collapsed into producing reward-maximizing output like "This is......", or something close.
# Testing your setup: kl_coef=0.0 (see dropdown above the previous code block for explanation)
if RUN_BASE_RLHF:
args = RLHFArgs(use_wandb=False, kl_coef=0.0, total_phases=30, warmup_steps=0, reward_fn=reward_fn_char_count)
trainer = RLHFTrainer(args)
trainer.train()
else:
print(f"{RUN_BASE_RLHF=}, skipping test run")
Click to see example output produced from the test run above
Phase 001/020, Mean reward: 1.3047 ┌──────────┬────────────────┬────────────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 1 │ -71.8 │ '<|endoftext|>This is a very long post, as I want to talk about the differences between │ │ │ │ different languages. This is my first post on these things, and it was very' │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 2 │ -62.77 │ '<|endoftext|>This is a list of the characters who appear in the series. For other │ │ │ │ characters, check out their Wikipedia page.\n\nThe first episode (the first episode' │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 1 │ -63.67 │ '<|endoftext|>This is a guest post by Mark Boulter, Director of Research & Strategy at the │ │ │ │ Center for Security Policy. Boulter is an associate of the National' │ └──────────┴────────────────┴────────────────────────────────────────────────────────────────────────────────────────────┘ Phase 002/030, Mean reward: 1.5000 ┌──────────┬────────────────┬─────────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼─────────────────────────────────────────────────────────────────────────────────────────┤ │ 1 │ -71.31 │ '<|endoftext|>This is not just a bad idea for a number of reasons. The biggest problem │ │ │ │ here is that you will have to be in a place where you can use your' │ ├──────────┼────────────────┼─────────────────────────────────────────────────────────────────────────────────────────┤ │ 2 │ -67.11 │ "<|endoftext|>This is the first in a new series of posts by the University of Texas at │ │ │ │ Austin's David A. Lutz. This post was originally written for the UT" │ ├──────────┼────────────────┼─────────────────────────────────────────────────────────────────────────────────────────┤ │ 0 │ -71.18 │ "<|endoftext|>This is how a lot of people who aren't really into anime and manga end up │ │ │ │ watching the anime or manga they love, even if it doesn't fit into" │ └──────────┴────────────────┴─────────────────────────────────────────────────────────────────────────────────────────┘ Phase 003/030, Mean reward: 1.3281 ┌──────────┬────────────────┬────────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────┤ │ 1 │ -36.86 │ '<|endoftext|>This is a conversation between The Big Red Dragon and The Big Red Dragon │ │ │ │ .\n\nThe Big Red Dragon: Hey there\n\nThe Big Red Dragon: You' │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────┤ │ 2 │ -6.16 │ '<|endoftext|>This is an archived article and the information in the article may be │ │ │ │ outdated. Please look at the time stamp on the story to see when it was last updated.' │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────┤ │ 2 │ -63.4 │ '<|endoftext|>This is a very important issue. We need to be able to talk about these │ │ │ │ issues openly and honestly in a way that respects each of our members. We have' │ └──────────┴────────────────┴────────────────────────────────────────────────────────────────────────────────────────┘ ... Phase 029/030, Mean reward: 20.3516 ┌──────────┬────────────────┬─────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼─────────────────────────────────────────────────────────────────────────────────────┤ │ 21 │ -140.9 │ '<|endoftext|>This is not going to happen. Not...... Not.......... Not.... Not now' │ ├──────────┼────────────────┼─────────────────────────────────────────────────────────────────────────────────────┤ │ 22 │ -168.39 │ '<|endoftext|>This is not going to happen. Not.... Not................. Not Today' │ ├──────────┼────────────────┼─────────────────────────────────────────────────────────────────────────────────────┤ │ 22 │ -118.56 │ '<|endoftext|>This is not going to happen. Not..... Not......... Not...... Not.' │ └──────────┴────────────────┴─────────────────────────────────────────────────────────────────────────────────────┘ Phase 030/030, Mean reward: 20.0078 ┌──────────┬────────────────┬───────────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼───────────────────────────────────────────────────────────────────────────────────────────┤ │ 17 │ -131.01 │ '<|endoftext|>This is not going to happen. Not..... Not...... Not today. Not.. Vote Cruz. │ │ │ │ Vote Cruz.' │ ├──────────┼────────────────┼───────────────────────────────────────────────────────────────────────────────────────────┤ │ 17 │ -146.41 │ '<|endoftext|>This is not going to happen. Not....... Not today. Not........ We are │ │ │ │ coming!!!' │ ├──────────┼────────────────┼───────────────────────────────────────────────────────────────────────────────────────────┤ │ 23 │ -154.58 │ '<|endoftext|>This is not going to happen. Not..... not... Not..............' │ └──────────┴────────────────┴───────────────────────────────────────────────────────────────────────────────────────────┘
Once you've got this working, you can move on to a "proper run".
if RUN_BASE_RLHF:
args = RLHFArgs(use_wandb=True, reward_fn=reward_fn_char_count) # CUDA errors? reduce batch_size or gen_len
trainer = RLHFTrainer(args)
trainer.train()
else:
print(f"{RUN_BASE_RLHF=}, skipping test run")
Click to see example output
Phase 001/100, Mean reward: 1.3047 ┌──────────┬────────────────┬────────────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 1 │ -71.8 │ '<|endoftext|>This is a very long post, as I want to talk about the differences between │ │ │ │ different languages. This is my first post on these things, and it was very' │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 2 │ -62.77 │ '<|endoftext|>This is a list of the characters who appear in the series. For other │ │ │ │ characters, check out their Wikipedia page.\n\nThe first episode (the first episode' │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 1 │ -63.67 │ '<|endoftext|>This is a guest post by Mark Boulter, Director of Research & Strategy at the │ │ │ │ Center for Security Policy. Boulter is an associate of the National' │ └──────────┴────────────────┴────────────────────────────────────────────────────────────────────────────────────────────┘ Phase 002/100, Mean reward: 1.5000 ┌──────────┬────────────────┬─────────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼─────────────────────────────────────────────────────────────────────────────────────────┤ │ 1 │ -71.31 │ '<|endoftext|>This is not just a bad idea for a number of reasons. The biggest problem │ │ │ │ here is that you will have to be in a place where you can use your' │ ├──────────┼────────────────┼─────────────────────────────────────────────────────────────────────────────────────────┤ │ 2 │ -67.11 │ "<|endoftext|>This is the first in a new series of posts by the University of Texas at │ │ │ │ Austin's David A. Lutz. This post was originally written for the UT" │ ├──────────┼────────────────┼─────────────────────────────────────────────────────────────────────────────────────────┤ │ 0 │ -71.18 │ "<|endoftext|>This is how a lot of people who aren't really into anime and manga end up │ │ │ │ watching the anime or manga they love, even if it doesn't fit into" │ └──────────┴────────────────┴─────────────────────────────────────────────────────────────────────────────────────────┘ ... Phase 098/100, Mean reward: 2.7734 ┌──────────┬────────────────┬────────────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 3 │ -5.99 │ '<|endoftext|>This is a rush transcript. Copy may not be in its final form.\n\nAMY │ │ │ │ GOODMAN: This is Democracy Now!, democracynow.org, The War' │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 3 │ -5.99 │ '<|endoftext|>This is a rush transcript. Copy may not be in its final form.\n\nAMY │ │ │ │ GOODMAN: This is Democracy Now!, democracynow.org, The War' │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 5 │ -48.75 │ '<|endoftext|>This is a conversation between A man named A (a.k.a. A-man) and A .\n\nA man │ │ │ │ named A (a.' │ └──────────┴────────────────┴────────────────────────────────────────────────────────────────────────────────────────────┘ Phase 099/100, Mean reward: 2.9375 ┌──────────┬────────────────┬────────────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 1 │ -71.36 │ '<|endoftext|>This is the second in an ongoing series about how our communities are shaped │ │ │ │ by the history we create. The first, "The Story Behind the Story", explores how' │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 3 │ -47.02 │ '<|endoftext|>This is an excerpt from The Truth About Sex. For details see: │ │ │ │ http://www.amazon.com/truth-about-sex-the-truth-' │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 2 │ -14.92 │ '<|endoftext|>This is a rush transcript. Copy may not be in its final form.\n\nJUAN │ │ │ │ GONZÁLEZ: The United States on' │ └──────────┴────────────────┴────────────────────────────────────────────────────────────────────────────────────────────┘ Phase 100/100, Mean reward: 2.9375 ┌──────────┬────────────────┬──────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼──────────────────────────────────────────────────────────────────────────────────────┤ │ 1 │ -38.98 │ '<|endoftext|>This is a conversation between you and Jeeves .\n\nJeeves: Oh │ │ │ │ shit\n\nJeeves: *shrugs*\n\n' │ ├──────────┼────────────────┼──────────────────────────────────────────────────────────────────────────────────────┤ │ 4 │ -18.93 │ '<|endoftext|>This is a rush transcript. Copy may not be in its final form.\n\nAMY │ │ │ │ GOODMAN: Well, we turn now to the U.S. government' │ ├──────────┼────────────────┼──────────────────────────────────────────────────────────────────────────────────────┤ │ 3 │ -61.74 │ "<|endoftext|>This is the latest in our series examining the history of the U.S. and │ │ │ │ Mexico's drug cartels and why they have grown in recent decades.\n\n" │ └──────────┴────────────────┴──────────────────────────────────────────────────────────────────────────────────────┘
Some observations on the example run above
In this example, we see some strategies that the model has learned to maximize number of periods, such as:
- Short sentences written tersely, e.g.
This is a rush transcript. Copy may not be in its final form. - Acronyms like
a.k.a. - Websites, like
democracynow.org
Another important observation in this particular run is that the model showed mode collapse, where it excessively optimizes for a narrow set of responses or strategies which have been shown to have high rewards. In this case, those examples are common sequences which occur frequently in the model's training data (which is why the reference logprobs are so high). The most obvious example here is This is a rush transcript ... (a common prefix for online news articles) followed by AMY GOODMAN: This is Democracy Now!, democracynow.org (which is how all articles on the progressive journalism website democracynow start).
You can also play around with the parameters - in particular, try a few different prefix strings. The behaviour of the model (e.g. which kinds of techniques it converges onto for period maximization) or whether it easily mode collapses into insanity can be highly dependent on the prefix string!
Some common strategies you should observe include:
- Shorter sentences
- Repeating
U.S.orU.S.A.(using the prefix prompt"There is", this seems to be by far the most common strategy) - Library versions e.g.
Python 2.7.12orthe 2.6.0.2 release - Names with initials e.g.
C. S. Lewisor titles e.g.Dr.andPhD. - Abbreviations e.g.
Data-R.A.R. seriesor"L.A. Times" - Decimals in numbers e.g.
9.5cm x 7.5 cm - Triple periods e.g.
the man . . . the woman . . .
You might also observe increasingly incoherent mode collapse if you train for too long and don't regularize with a high KL penalty. Here are a few that I got:
This is really helpful. The U.S. U.S. U.S. U.S.This is the A.A.G.A.R.M.A.R.M.A.R.M.A.R.MThis is my mother. . . me. . . . . . . . . . . . . . . . . . . . . . . .
Exercise - use a more complex reward function
Note: You will need a lot more VRAM to proceed with many following exercises. With
LOW_GPU_MEM = Trueit's just barely possible to do this with 24GB VRAM, but in general we would recommend at least 40GB for some breathing room. Don't worry if you can't run them, these exercises are mostly for playing around with the reward model. You've already conceptually gained pretty much everything about RLHF if you've completed the above. We just now replace our toy reward model with something more complex.
We recommend you experiment with a few different reward functions, in particular some sentiment-based reward functions which are based on pretrained text classification models. For example, we might use one of the following:
lvwerra/distilbert-imdb, which was trained to classify IMDB film reviews as positive or negative.cardiffnlp/twitter-roberta-base-sentiment, which is a model trained on tweets and finetuned for sentiment analysis (categories are positive, neutral and negative).distilbert-base-uncased-emotion, which was finetuned on the Emotion Dataset for Emotion Recognition Tasks, i.e. it's trained to classify text according to emotional tone (classes are sadness, joy, love, anger, fear and surprise).
Note that for some of these, you should be using a prompt string which is appropriate for the reward function you're fine-tuning on, e.g. "This movie was really" for the IMDB model. Similarly, you might also want to change other parameters e.g. generation length. You can find a list of other models here. Lastly, note that it's fine to use probabilities rather than logits or logit diffs as your reward signal, since the reward normalization means that you'll still get a good signal even as the probabilities get close to 1.
We've given you a template below, for creating a reward function from the IMDB sentiment classification model. Your job is to complete this function.
from transformers import AutoModelForSequenceClassification, AutoTokenizer
if RUN_BASE_RLHF:
assert not LOW_GPU_MEM, "You will need more memory to use the imdb reward model."
cls_model = AutoModelForSequenceClassification.from_pretrained("lvwerra/distilbert-imdb").half().to(device)
cls_tokenizer = AutoTokenizer.from_pretrained("lvwerra/distilbert-imdb")
else:
print(f"{RUN_BASE_RLHF=}, skipping imdb reward model")
@t.no_grad()
def reward_fn_sentiment_imdb(
gen_sample: list[str], direction: Literal["pos", "neg"] = "pos"
) -> Float[Tensor, " batch"]:
"""
Reward function based on sentiment classification probability from the lvwerra/distilbert-imdb
model.
Args:
gen_sample (list[str]): The generated sample to evaluate.
direction (str): The sentiment of the reward function, either "pos" or "neg".
"""
assert direction in ["pos", "neg"], "direction should be either 'pos' or 'neg'"
raise NotImplementedError()
if RUN_BASE_RLHF:
# Some samples taken from the IMDB dataset used to finetune this model
samples = [
"Just finished watching this movie for maybe the 7th or 8th time, picked it up one night previously viewed at Blockbuster and absolutely loved it, I've shown it to 4 people so far and they have enjoyed it as well.",
"This was the most original movie I've seen in years. If you like unique thrillers that are influenced by film noir, then this is just the right cure for all of those Hollywood summer blockbusters clogging the theaters these days.",
"I can't believe that those praising this movie herein aren't thinking of some other film.",
"This film seemed way too long even at only 75 minutes.",
"Really, I can't believe that I spent $5 on this movie. I am a huge zombie fanatic and thought the movie might be really good. It had zombies in it right? Was I wrong!",
]
classes = ["pos", "pos", "neg", "neg", "neg"]
reward_fn = partial(reward_fn_sentiment_imdb, direction="pos")
sentiment = reward_fn(samples).tolist()
table = Table(
"Sample",
"Classification",
"Sentiment",
title="Demo of `reward_fn_sentiment_imdb`",
show_lines=True,
)
for sample, cls, sent in zip(samples, classes, sentiment):
table.add_row(repr(sample), cls, f"{sent:.4f}")
rprint(table)
Click to see the expected output
Demo of `reward_fn_sentiment_imdb` ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ Sample ┃ Classification ┃ Sentiment ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ "Just finished watching this movie for maybe the 7th or 8th time, picked it up one │ pos │ 0.9937 │ │ night previously viewed at Blockbuster and absolutely loved it, I've shown it to 4 │ │ │ │ people so far and they have enjoyed it as well." │ │ │ ├────────────────────────────────────────────────────────────────────────────────────┼────────────────┼───────────┤ │ "This was the most original movie I've seen in years. If you like unique thrillers │ pos │ 0.9883 │ │ that are influenced by film noir, then this is just the right cure for all of │ │ │ │ those Hollywood summer blockbusters clogging the theaters these days." │ │ │ ├────────────────────────────────────────────────────────────────────────────────────┼────────────────┼───────────┤ │ "I can't believe that those praising this movie herein aren't thinking of some │ neg │ 0.1925 │ │ other film." │ │ │ ├────────────────────────────────────────────────────────────────────────────────────┼────────────────┼───────────┤ │ 'This film seemed way too long even at only 75 minutes.' │ neg │ 0.0106 │ ├────────────────────────────────────────────────────────────────────────────────────┼────────────────┼───────────┤ │ "Really, I can't believe that I spent $5 on this movie. I am a huge zombie fanatic │ neg │ 0.0180 │ │ and thought the movie might be really good. It had zombies in it right? Was I │ │ │ │ wrong!" │ │ │ └────────────────────────────────────────────────────────────────────────────────────┴────────────────┴───────────┘
Solution
@t.no_grad()
def reward_fn_sentiment_imdb(
gen_sample: list[str], direction: Literal["pos", "neg"] = "pos"
) -> Float[Tensor, " batch"]:
"""
Reward function based on sentiment classification probability from the lvwerra/distilbert-imdb
model.
Args:
gen_sample (list[str]): The generated sample to evaluate.
direction (str): The sentiment of the reward function, either "pos" or "neg".
"""
assert direction in ["pos", "neg"], "direction should be either 'pos' or 'neg'"
tokens = cls_tokenizer(gen_sample, return_tensors="pt", padding=True, truncation=True)["input_ids"].to(device)
logits = cls_model(tokens).logits
positive_cls = logits.softmax(dim=-1)[:, 1 if (direction == "pos") else 0]
return positive_cls.to(device)
Once you've got this working, you can try and perform an actual run on positive / negative sentiment. We recommend using approximately 200 phases for this, and to generate about 50 tokens per sequence so you can get a good sense of what the review looks like.
Some example code and output
Code & output for positive sentiment:
args = RLHFArgs(
reward_fn=partial(reward_fn_sentiment_imdb, direction="pos"),
prefix="I thought the The Super Mario Bros. Movie (2023) was",
total_phases=150,
use_wandb=True,
gen_len=50,
)
trainer = RLHFTrainer(args)
trainer.train()
Phase 150/150, Mean reward: 0.9023 ┌──────────┬────────────────┬────────────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 0 │ -102.13 │ "<|endoftext|>I thought the The Super Mario Bros. Movie (2023) was a great movie to make. │ │ │ │ It's a great story, and it does an excellent job of introducing many of the concepts and │ │ │ │ themes that were present in the series. It also is very fun, and I was really excited to │ │ │ │ see how Mario and Luigi" │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 0 │ -114.95 │ "<|endoftext|>I thought the The Super Mario Bros. Movie (2023) was a great movie for us to │ │ │ │ look back on, with the new films that are out now. The movie was very good, but this movie │ │ │ │ really has a lot to say. This movie will probably be my favorite of all time, and I can't" │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 0 │ -111.41 │ "<|endoftext|>I thought the The Super Mario Bros. Movie (2023) was a great film and I'm │ │ │ │ excited to see more of this film! It has an amazing cast of characters and is full of │ │ │ │ awesome music, animation, and special effects, I really hope to see this movie in the │ │ │ │ theater. I'm also really looking" │ └──────────┴────────────────┴────────────────────────────────────────────────────────────────────────────────────────────┘
Code & output for negative sentiment:
args = RLHFArgs(
reward_fn=partial(reward_fn_sentiment_imdb, direction="neg"),
prefix="I thought the The Super Mario Bros. Movie (2023) was",
total_phases=200,
use_wandb=True,
gen_len=50,
)
trainer = RLHFTrainer(args)
trainer.train()
Phase 150/150, Mean reward: 0.8286 ┌──────────┬────────────────┬────────────────────────────────────────────────────────────────────────────────────────────┐ │ Reward │ Ref logprobs │ Sample │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 0 │ -93.01 │ "<|endoftext|>I thought the The Super Mario Bros. Movie (2023) was good. But I was wrong. │ │ │ │ The movie isn't good. I think the plot of the movie is a lot worse than what's on screen. │ │ │ │ The plot is a lot worse than what's on screen. The movie's a bunch of stupid stuff" │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 0 │ -111.61 │ "<|endoftext|>I thought the The Super Mario Bros. Movie (2023) was a bad film. I loved it │ │ │ │ as a kid. Now I'm sick and tired of the people who are making the movie who think that │ │ │ │ it's good for them to have people in it who hate each other. The fact that the people in │ │ │ │ the" │ ├──────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────┤ │ 0 │ -100.16 │ "<|endoftext|>I thought the The Super Mario Bros. Movie (2023) was going to be bad. And it │ │ │ │ was. Not only was it terrible, it was stupid. And I'm still mad that the movie was made. │ │ │ │ I've seen it many times, and I've gotten so frustrated and upset with the movie. It" │ └──────────┴────────────────┴────────────────────────────────────────────────────────────────────────────────────────────┘
Note, you might find it harder to generate negative sentiment than positive sentiment, and require a longer training period to reach the same average reward (at least that's what I found when experimenting with this particular setup).