[1.4.1] Indirect Object Identification
Please send any problems / bugs on the #errata channel in the Slack group, and ask any questions on the dedicated channels for this chapter of material.
If you want to change to dark mode, you can do this by clicking the three horizontal lines in the top-right, then navigating to Settings → Theme.
Links to all other chapters: (0) Fundamentals, (1) Transformer Interpretability, (2) RL.

Introduction
This notebook / document is built around the Interpretability in the Wild paper, in which the authors aim to understand the indirect object identification circuit in GPT-2 small. This circuit is responsible for the model's ability to complete sentences like "John and Mary went to the shops, John gave a bag to" with the correct token "" Mary".
It is loosely divided into different sections, each one with their own flavour. Sections 1, 2 & 3 are derived from Neel Nanda's notebook Exploratory_Analysis_Demo. The flavour of these exercises is experimental and loose, with a focus on demonstrating what exploratory analysis looks like in practice with the transformerlens library. They skimp on rigour, and instead try to speedrun the process of finding suggestive evidence for this circuit. The code and exercises are simple and generic, but accompanied with a lot of detail about what each stage is doing, and why (plus several optional details and tangents). Section 4 introduces you to the idea of path patching, which is a more rigorous and structured way of analysing the model's behaviour. Here, you'll be replicating some of the results of the paper, which will serve to rigorously validate the insights gained from earlier sections. It's the most technically dense of all five sections. Lastly, sections 5 & 6 are much less structured, and have a stronger focus on open-ended exercises & letting you go off and explore for yourself.
Which exercises you want to do will depend on what you're hoping to get out of these exercises. For example:
- You want to understand activation patching - 1, 2, 3
- You want to get a sense of how to do exploratory analysis on a model - 1, 2, 3
- You want to understand activation and path patching - 1, 2, 3, 4
- You want to understand the IOI circuit fully, and replicate the paper's key results - 1, 2, 3, 4, 5
- You want to understand the IOI circuit fully, and replicate the paper's key results (but you already understand activation patching) - 1, 2, 4, 5
- You want to understand IOI, and then dive deeper e.g. by looking for more circuits in models or investigating anomalies - 1, 2, 3, 4, 5, 6
Note - if you find yourself getting frequent CUDA memory errors, you can periodically call torch.cuda.empty_cache() to free up some memory.
Each exercise will have a difficulty and importance rating out of 5, as well as an estimated maximum time you should spend on these exercises and sometimes a short annotation. You should interpret the ratings & time estimates relatively (e.g. if you find yourself spending about 50% longer on the exercises than the time estimates, adjust accordingly). Please do skip exercises / look at solutions if you don't feel like they're important enough to be worth doing, and you'd rather get to the good stuff!
The purpose / structure of these exercises
At a surface level, these exercises are designed to take you through the indirect object identification circuit. But it's also designed to make you a better interpretability researcher! As a result, most exercises will be doing a combination of:
- Showing you some new feature/component of the circuit, and
- Teaching you how to use tools and interpret results in a broader mech interp context.
A key idea to have in mind during these exercises is the spectrum from simpler, more exploratory tools to more rigorous, complex tools. On the simpler side, you have something like inspecting attention patterns, which can give a decent (but sometimes misleading) picture of what an attention head is doing. These should be some of the first tools you reach for, and you should be using them a lot even before you have concrete hypotheses about a circuit. On the more rigorous side, you have something like path patching, which is a pretty rigorous and effortful tool that is best used when you already have reasonably concrete hypotheses about a circuit. As we go through the exercises, we'll transition from left to right along this spectrum.
The IOI task
The first step when trying to reverse engineer a circuit in a model is to identify what capability we want to reverse engineer. Indirect Object Identification is a task studied in Redwood Research's excellent Interpretability in the Wild paper (see Neel Nanda's interview with the authors or Kevin Wang's Twitter thread for an overview). The task is to complete sentences like "When Mary and John went to the store, John gave a drink to" with " Mary" rather than " John".
In the paper they rigorously reverse engineer a 26 head circuit, with 7 separate categories of heads used to perform this capability. The circuit they found roughly breaks down into three parts:
- Identify what names are in the sentence
- Identify which names are duplicated
- Predict the name that is not duplicated
Why was this task chosen? The authors give a very good explanation for their choice in their video walkthrough of their paper, which you are encouraged to watch. To be brief, some of the reasons were:
- This is a fairly common grammatical structure, so we should expect the model to build some circuitry for solving it quite early on (after it's finished with all the more basic stuff, like n-grams, punctuation, induction, and simpler grammatical structures than this one).
- It's easy to measure: the model always puts a much higher probability on the IO and S tokens (i.e.
" Mary"and" John") than any others, and this is especially true once the model starts being stripped down to the core part of the circuit we're studying. So we can just take the logit difference between these two tokens, and use this as a metric for how well the model can solve the task. - It is a crisp and well-defined task, so less likely to be solved in terms of memorisation of a large bag of heuristics (unlike e.g. tasks like "predict that the number
n+1will follown, which as Neel mentions in the video walkthrough is actually much more annoying and subtle than it first seems!).
A terminology note: IO will refer to the indirect object (in the example, " Mary"), S1 and S2 will refer to the two instances of the subject token (i.e. " John"), and end will refer to the end token " to" (because this is the position we take our prediction from, and we don't care about any tokens after this point). We will also sometimes use S to refer to the identity of the subject token (rather than referring to the first or second instance in particular).
Keeping track of your guesses & predictions
There's a lot to keep track of in these exercises as we work through them. You'll be exposed to new functions and modules from transformerlens, new ways to causally intervene in models, all the while building up your understanding of how the IOI task is performed. The notebook starts off exploratory in nature (lots of plotting and investigation), and gradually moves into more technical details, refined analysis, and replication of the paper's results, as we improve our understanding of the IOI circuit. You are recommended to keep a document or page of notes nearby as you go through these exercises, so you can keep track of the main takeaways from each section, as well as your hypotheses for how the model performs the task, and your ideas for how you might go off and test these hypotheses on your own if the notebook were to suddenly end.
If you are feeling extremely confused at any point, you can come back to the dropdown below, which contains diagrams explaining how the circuit works. There is also an accompanying intuitive explanation which you might find more helpful. However, I'd recommend you try and go through the notebook unassisted before looking at these.
Intuitive explanation of IOI circuit
First, let's start with an analogy for how transformers work (you can skip this if you've already read my post). Imagine a line of people, who can only look forward. Each person has a token written on their chest, and their goal is to figure out what token the person in front of them is holding. Each person is allowed to pass a question backwards along the line (not forwards), and anyone can choose to reply to that question by passing information forwards to the person who asked. In this case, the sentence is "When Mary and John went to the store, John gave a drink to Mary". You are the person holding the " to" token, and your goal is to figure out that the person in front of him has the " Mary" token.
To be clear about how this analogy relates to transformers: * Each person in the line represents a vector in the residual stream. Initially they just store their own token, but they accrue more information as they ask questions and receive answers (i.e. as components write to the residual stream) * The operation of an attention head is represented by a question & answer: * The person who asks is the destination token, the people who answer are the source tokens * The question is the query vector * The information which determines who answers the question is the key vector * The information which gets passed back to the original asker is the value vector
Now, here is how the IOI circuit works in this analogy. Each bullet point represents a class of attention heads.
- The person with the second
" John"token asks the question "does anyone else hold the name" John"?". They get a reply from the first" John"token, who also gives him their location. So he now knows that" John"is repeated, and he knows that the first" John"token is 4th in the sequence.- These are Duplicate Token Heads
- You ask the question "which names are repeated?", and you get an answer from the person holding the second
" John"token. You now also know that" John"is repeated, and where the first" John"token is.- These are S-Inhibition Heads
- You ask the question "does anyone have a name that isn't
" John", and isn't at the 4th position in the sequence?". You get a reply from the person holding the" Mary"token, who tells you that they have name" Mary". You use this as your prediction.- These are Name Mover Heads
This is a fine first-pass understanding of how the circuit works. A few other features:
- The person after the first
" John"(holding" went") had previously asked about the identity of the person behind him. So he knows that the 4th person in the sequence holds the" John"token, meaning he can also reply to the question of the person holding the second" John"token. (previous token heads / induction heads)- This might not seem necessary, but since previous token heads / induction heads are just a pretty useful thing to have in general, it makes sense that you'd want to make use of this information!
- If for some reason you forget to ask the question "does anyone have a name that isn't
" John", and isn't at the 4th position in the sequence?", then you'll have another chance to do this.- These are (Backup Name Mover Heads)
- Their existence might be partly because transformers are trained with dropout. This can make them "forget" things, so it's important to have a backup method for recovering that information!
- You want to avoid overconfidence, so you also ask the question "does anyone have a name that isn't
" John", and isn't at the 4th position in the sequence?" another time, in order to anti-predict the response that you get from this question. (negative name mover heads)- Yes, this is as weird as it sounds! The authors speculate that these heads "hedge" the predictions, avoiding high cross-entropy loss when making mistakes.
Diagram 1 (simple)
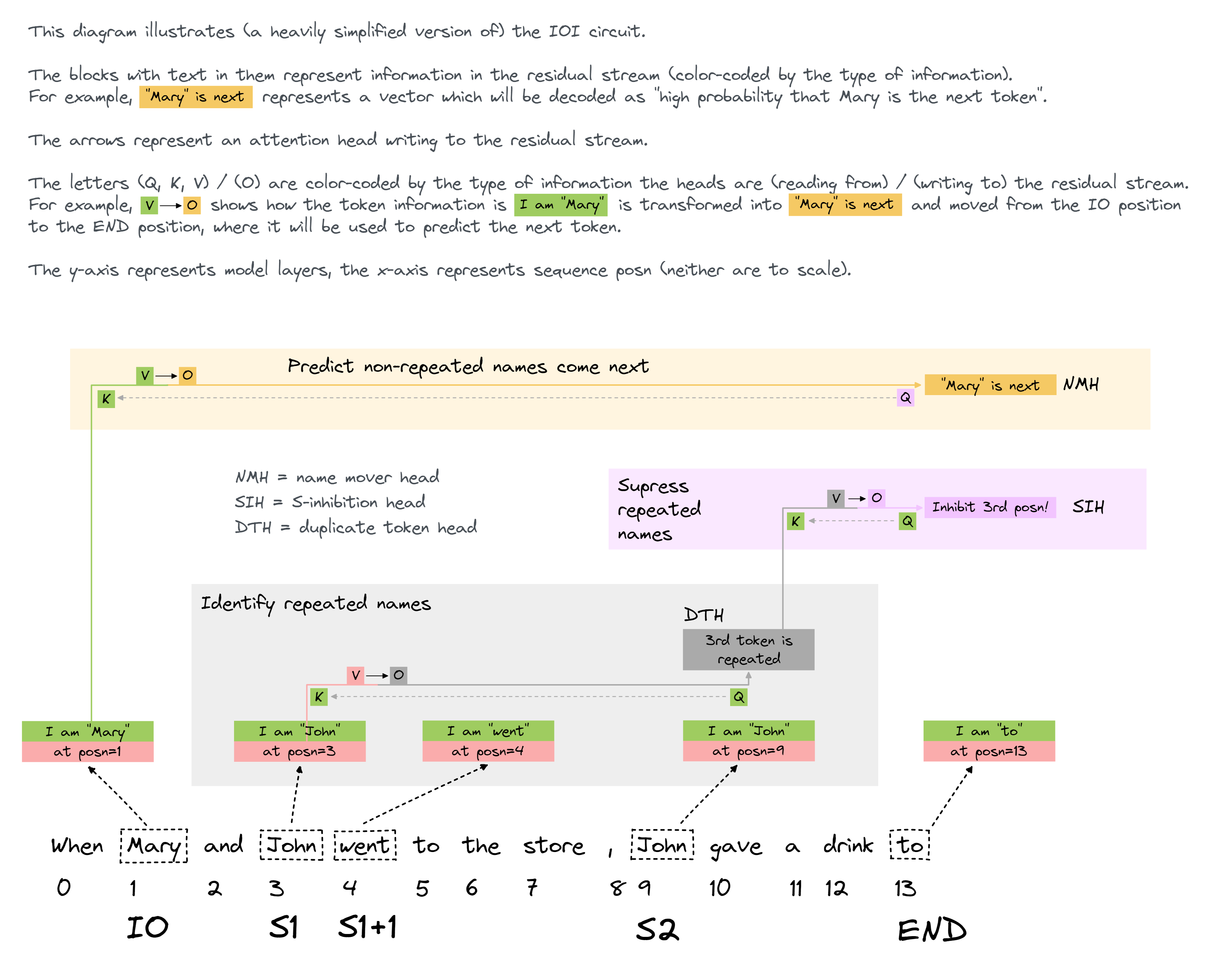
Diagram 2 (complex)

Content & Learning Objectives
1️⃣ Model & Task Setup
In this section you'll set up your model, and see how to analyse its performance on the IOI task. You'll also learn how to measure its performance using tools like logit difference.
Learning Objectives
- Understand the IOI task, and why the authors chose to study it
- Build functions to demonstrate the model's performance on this task
2️⃣ Logit Attribution
Next, you'll move on to some component attribution: evaluating the importance of each model component for the IOI task. However, this type of analysis is limited to measuring a component's direct effect, as opposed to indirect effect - we'll measure the latter in future sections.
Learning Objectives
- Perform direct logit attribution to figure out which heads are writing to the residual stream in a significant way
- Learn how to use different transformerlens helper functions, which decompose the residual stream in different ways
3️⃣ Activation Patching
We introduce one of the two important patching tools you'll use during this section: activation patching. This can be used to discover which components of a model are important for a particular task, by measuring the changes in our previously-defined task metrics when you patch into a particular component with corrupted input.
Learning Objectives
- Understand the idea of activation patching, and how it can be used
- Implement some of the activation patching helper functions in transformerlens from scratch (i.e. using hooks)
- Use activation patching to track the layers & sequence positions in the residual stream where important information is stored and processed
- By the end of this section, you should be able to draw a rough sketch of the IOI circuit
4️⃣ Path Patching
Next, we move to path patching, a more refined form of activation patching which examines the importance of particular paths between model components. This will give us a more precise picture of how our circuit works.
Learning Objectives
- Understand the idea of path patching, and how it differs from activation patching
- Implement path patching from scratch (i.e. using hooks)
- Replicate several of the results in the IOI paper
5️⃣ Full Replication: Minimal Circuits and more
Lastly, we'll do some cleaning up, by replicating some other results from the IOI paper. This includes implementing a complex form of ablation which removes every component from the model except for the ones we've identified from previous analysis, and showing that the performance is recovered. This section is more open-ended and less structured.
Learning Objectives
- Replicate most of the other results from the IOI paper
- Practice more open-ended, less guided coding
☆ Bonus / exploring anomalies
We end with a few suggested bonus exercises for this particular circuit, as well as ideas for capstone projects / paper replications.
Learning Objectives
- Explore other parts of the model (e.g. negative name mover heads, and induction heads)
- Understand the subtleties present in model circuits, and the fact that there are often more parts to a circuit than seem obvious after initial investigation
- Understand the importance of the three quantitative criteria used by the paper: faithfulness, completeness and minimality
Setup code
import re
import sys
from functools import partial
from itertools import product
from pathlib import Path
from typing import Callable, Literal
import circuitsvis as cv
import einops
import numpy as np
import plotly.express as px
import torch as t
from IPython.display import HTML, display
from jaxtyping import Bool, Float, Int
from rich import print as rprint
from rich.table import Column, Table
from torch import Tensor
from tqdm.notebook import tqdm
from transformer_lens import ActivationCache, HookedTransformer, utils
from transformer_lens.components import MLP, Embed, LayerNorm, Unembed
from transformer_lens.hook_points import HookPoint
t.set_grad_enabled(False)
device = t.device("mps" if t.backends.mps.is_available() else "cuda" if t.cuda.is_available() else "cpu")
# Make sure exercises are in the path
chapter = "chapter1_transformer_interp"
section = "part41_indirect_object_identification"
root_dir = next(p for p in Path.cwd().parents if (p / chapter).exists())
exercises_dir = root_dir / chapter / "exercises"
section_dir = exercises_dir / section
if str(exercises_dir) not in sys.path:
sys.path.append(str(exercises_dir))
import part41_indirect_object_identification.tests as tests
from plotly_utils import bar, imshow, line, scatter
MAIN = __name__ == "__main__"