2️⃣ Task-encoding hidden states
Learning Objectives
- Understand how
nnsightcan be used to perform causal interventions, and perform some yourself- Reproduce the "h-vector results" from the function vectors paper; that the residual stream does contain a vector which encodes the task and can induce task behaviour on zero-shot prompts
We'll begin with the following question, posed by the Function Vectors paper:
When a transformer processes an ICL (in-context-learning) prompt with exemplars demonstrating task $T$, do any hidden states encode the task itself?
We'll prove that the answer is yes, by constructing a vector $h$ from a set of ICL prompts for the antonym task, and intervening with our vector to make our model produce antonyms on zero-shot prompts.
This will require you to learn how to perform causal interventions with nnsight, not just save activations.
Note - this section structurally follows section 2.1 of the function vectors paper.
ICL Task
Exercise (optional) - generate your own antonym pairs
We've provided you two options for the antonym dataset you'll use in these exercises.
- Firstly, we've provided you a list of word pairs, in the file
data/antonym_pairs.txt. - Secondly, if you want to run experiments like the ones in this paper, it can be good practice to learn how to generate prompts from GPT-4 or other models (this is how we generated the data for this exercise).
If you just want to use the provided list of words, skip this exercise and run the code below to load in the dataset from the text file. Alternatively, if you want to generate your own dataset, you can fill in the function generate_dataset below, which should query GPT-4 and get a list of antonym pairs.
See here for a guide to using the chat completions API, if you haven't already used it. Use the two dropdowns below (in order) for some guidance.
Getting started #1
Here is a recommended template:
client = OpenAI(api_key=api_key)
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": antonym_task},
{"role": "assistant", "content": start_of_response},
]
)
where antonym_task explains the antonym task, and start_of_respose gives the model a prompt to start from (e.g. "Sure, here are some antonyms: ..."), to guide its subsequent behaviour.
Getting started #2
Here is an template you might want to use for the actual request:
example_antonyms = "old: young, top: bottom, awake: asleep, future: past, "
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f"Give me {N} examples of antonym pairs. They should be obvious, i.e. each word should be associated with a single correct antonym."},
{"role": "assistant", "content": f"Sure! Here are {N} pairs of antonyms satisfying this specification: {example_antonyms}"},
]
)
where N is the function argument. Note that we've provided a few example antonyms, and appended them to the start of GPT4's completion. This is a classic trick to guide the rest of the output (in fact, it's commonly used in adversarial attacks).
Note - it's possible that not all the antonyms returned will be solvable by GPT-J. In this section, we won't worry too much about this. When it comes to testing out our zero-shot intervention, we'll make sure to only use cases where GPT-J can actually solve it.
def generate_antonym_dataset(N: int):
"""
Generates 100 pairs of antonyms, in the form of a list of 2-tuples.
"""
assert os.environ.get("OPENAI_API_KEY", None) is not None, (
"Please set your API key before running this function!"
)
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": f"Generate {N} pairs of antonyms in the form of a list of 2-tuples. For example, [['old', 'young'], ['top', bottom'], ['awake', 'asleep']...].",
},
{"role": "assistant", "content": "Sure, here is a list of 100 antonyms: "},
],
)
return response
if os.environ.get("OPENAI_API_KEY", None) is not None:
ANTONYM_PAIRS = generate_antonym_dataset(100)
# Save the word pairs in a text file
with open(section_dir / "data" / "my_antonym_pairs.txt", "w") as f:
for word_pair in ANTONYM_PAIRS:
f.write(f"{word_pair[0]} {word_pair[1]}\n")
# Load the word pairs from the text file
with open(section_dir / "data" / "antonym_pairs.txt", "r") as f:
ANTONYM_PAIRS = [line.split() for line in f.readlines()]
print(ANTONYM_PAIRS[:10])
[
["old", "young"],
["top", "bottom"],
["awake", "asleep"],
["future", "past"],
["appear", "disappear"],
["early", "late"],
["empty", "full"],
["innocent", "guilty"],
["ancient", "modern"],
["arrive", "depart"],
]
ICL Dataset
To handle this list of word pairs, we've given you some helpful classes.
Firstly, there's the ICLSequence class, which takes in a list of word pairs and contains methods for constructing a prompt (and completion) from these words. Run the code below to see how it works.
class ICLSequence:
"""
Class to store a single antonym sequence.
Uses the default template "Q: {x}\nA: {y}" (with separate pairs split by "\n\n").
"""
def __init__(self, word_pairs: list[list[str]]):
self.word_pairs = word_pairs
self.x, self.y = zip(*word_pairs)
def __len__(self):
return len(self.word_pairs)
def __getitem__(self, idx: int):
return self.word_pairs[idx]
def prompt(self):
"""Returns the prompt, which contains all but the second element in the last word pair."""
p = "\n\n".join([f"Q: {x}\nA: {y}" for x, y in self.word_pairs])
return p[: -len(self.completion())]
def completion(self):
"""Returns the second element in the last word pair (with padded space)."""
return " " + self.y[-1]
def __str__(self):
"""Prints a readable string representation of the prompt & completion (indep of template)."""
return f"{', '.join([f'({x}, {y})' for x, y in self[:-1]])}, {self.x[-1]} ->".strip(", ")
word_list = [["hot", "cold"], ["yes", "no"], ["in", "out"], ["up", "down"]]
seq = ICLSequence(word_list)
print("Tuple-representation of the sequence:")
print(seq)
print("\nActual prompt, which will be fed into the model:")
print(seq.prompt())
Tuple-representation of the sequence: (hot, cold), (yes, no), (in, out), up -> Actual prompt, which will be fed into the model: Q: hot A: cold Q: yes A: no Q: in A: out Q: up A:
Secondly, we have the ICLDataset class. This is also fed a word pair list, and it has methods for generating batches of prompts and completions. It can generate both clean prompts (where each pair is actually an antonym pair) and corrupted prompts (where the answers for each pair are randomly chosen from the dataset).
class ICLDataset:
"""
Dataset to create antonym pair prompts, in ICL task format. We use random seeds for consistency
between the corrupted and clean datasets.
Inputs:
word_pairs:
list of ICL task, e.g. [["old", "young"], ["top", "bottom"], ...] for the antonym task
size:
number of prompts to generate
n_prepended:
number of antonym pairs before the single-word ICL task
bidirectional:
if True, then we also consider the reversed antonym pairs
corrupted:
if True, then the second word in each pair is replaced with a random word
seed:
random seed, for consistency & reproducibility
"""
def __init__(
self,
word_pairs: list[list[str]],
size: int,
n_prepended: int,
bidirectional: bool = True,
seed: int = 0,
corrupted: bool = False,
):
assert n_prepended + 1 <= len(word_pairs), (
"Not enough antonym pairs in dataset to create prompt."
)
self.word_pairs = word_pairs
self.word_list = [word for word_pair in word_pairs for word in word_pair]
self.size = size
self.n_prepended = n_prepended
self.bidirectional = bidirectional
self.corrupted = corrupted
self.seed = seed
self.seqs = []
self.prompts = []
self.completions = []
# Generate the dataset (by choosing random word pairs, and constructing ICLSequence objects)
for n in range(size):
np.random.seed(seed + n)
random_pairs = np.random.choice(len(self.word_pairs), n_prepended + 1, replace=False)
# Randomize the order of each word pair (x, y).
# If not bidirectional, we always have x -> y not y -> x
random_orders = np.random.choice([1, -1], n_prepended + 1)
if not (bidirectional):
random_orders[:] = 1
word_pairs = [
self.word_pairs[pair][::order] for pair, order in zip(random_pairs, random_orders)
]
# If corrupted, then replace y with a random word in all (x, y) pairs except the last one
if corrupted:
for i in range(len(word_pairs) - 1):
word_pairs[i][1] = np.random.choice(self.word_list)
seq = ICLSequence(word_pairs)
self.seqs.append(seq)
self.prompts.append(seq.prompt())
self.completions.append(seq.completion())
def create_corrupted_dataset(self):
"""Creates a corrupted version of the dataset (with same random seed)."""
return ICLDataset(
self.word_pairs,
self.size,
self.n_prepended,
self.bidirectional,
corrupted=True,
seed=self.seed,
)
def __len__(self):
return self.size
def __getitem__(self, idx: int):
return self.seqs[idx]
You can see how this dataset works below. Note that the correct completions have a prepended space, because this is how the antonym prompts are structured - the answers are tokenized as "A: answer" -> ["A", ":", " answer"]. Forgetting prepended spaces is a classic mistake when working with transformers!
dataset = ICLDataset(ANTONYM_PAIRS, size=10, n_prepended=2, corrupted=False)
table = Table("Prompt", "Correct completion")
for seq, completion in zip(dataset.seqs, dataset.completions):
table.add_row(str(seq), repr(completion))
rprint(table)
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┓ ┃ Prompt ┃ Correct completion ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━┩ │ (right, left), (maximum, minimum), melt -> │ ' freeze' │ │ (minimum, maximum), (old, new), punishment -> │ ' reward' │ │ (arrogant, humble), (blunt, sharp), compulsory -> │ ' voluntary' │ │ (inside, outside), (freeze, melt), full -> │ ' empty' │ │ (reject, accept), (awake, asleep), dusk -> │ ' dawn' │ │ (invisible, visible), (punishment, reward), heavy -> │ ' light' │ │ (victory, defeat), (forward, backward), young -> │ ' old' │ │ (up, down), (compulsory, voluntary), right -> │ ' wrong' │ │ (open, closed), (domestic, foreign), brave -> │ ' cowardly' │ │ (under, over), (past, future), increase -> │ ' decrease' │ └──────────────────────────────────────────────────────┴────────────────────┘
Compare this output to what it looks like when corrupted=True. In the prompt, each pair before the last one has their second element replaced with a random one (e.g. (right, left) becomes (right, pivate)) but the last pair is left unchanged. This should effectively destroy the model's ability to infer what pattern the pairs are following.
dataset = ICLDataset(ANTONYM_PAIRS, size=10, n_prepended=2, corrupted=True)
table = Table("Prompt", "Correct completion")
for seq, completions in zip(dataset.seqs, dataset.completions):
table.add_row(str(seq), repr(completions))
rprint(table)
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┓ ┃ Prompt ┃ Correct completion ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━┩ │ (right, private), (maximum, destroy), melt -> │ ' freeze' │ │ (minimum, increase), (old, sharp), punishment -> │ ' reward' │ │ (arrogant, humble), (blunt, deep), compulsory -> │ ' voluntary' │ │ (inside, voluntary), (freeze, exterior), full -> │ ' empty' │ │ (reject, profit), (awake, start), dusk -> │ ' dawn' │ │ (invisible, birth), (punishment, spend), heavy -> │ ' light' │ │ (victory, rich), (forward, honest), young -> │ ' old' │ │ (up, lie), (compulsory, short), right -> │ ' wrong' │ │ (open, soft), (domestic, anxious), brave -> │ ' cowardly' │ │ (under, melt), (past, young), increase -> │ ' decrease' │ └───────────────────────────────────────────────────┴────────────────────┘
Aside - the rich library
The rich library is a helpful little library to display outputs more clearly in a Python notebook or terminal. It's not necessary for this workshop, but it's a nice little tool to have in your toolbox.
The most important function is rich.print (usually imported as rprint). This can print basic strings, but it also supports the following syntax for printing colors:
rprint("[green]This is green text[/], this is default color")

and for making text bold / underlined:
rprint("[u dark_orange]This is underlined[/], and [b cyan]this is bold[/].")

It can also print tables:
from rich.table import Table
table = Table("Col1", "Col2", title="Title") # title is optional
table.add_row("A", "a")
table.add_row("B", "b")
rprint(table)

The text formatting (bold, underlined, colors, etc) is also supported within table cells.
Task-encoding vector
Exercise - forward pass on antonym dataset
You should fill in the calculate_h function below. It should:
- Run a forward pass on the model with the dataset prompts (i.e. the
.promptsattribute), using thennsightsyntax we've demonstrated previously, - Return a tuple of the model's output (i.e. a list of its string-token completions, one for each prompt in the batch) and the residual stream value at the end of layer
layer(e.g. iflayer = -1, this means the final value of the residual stream before we convert into logits).
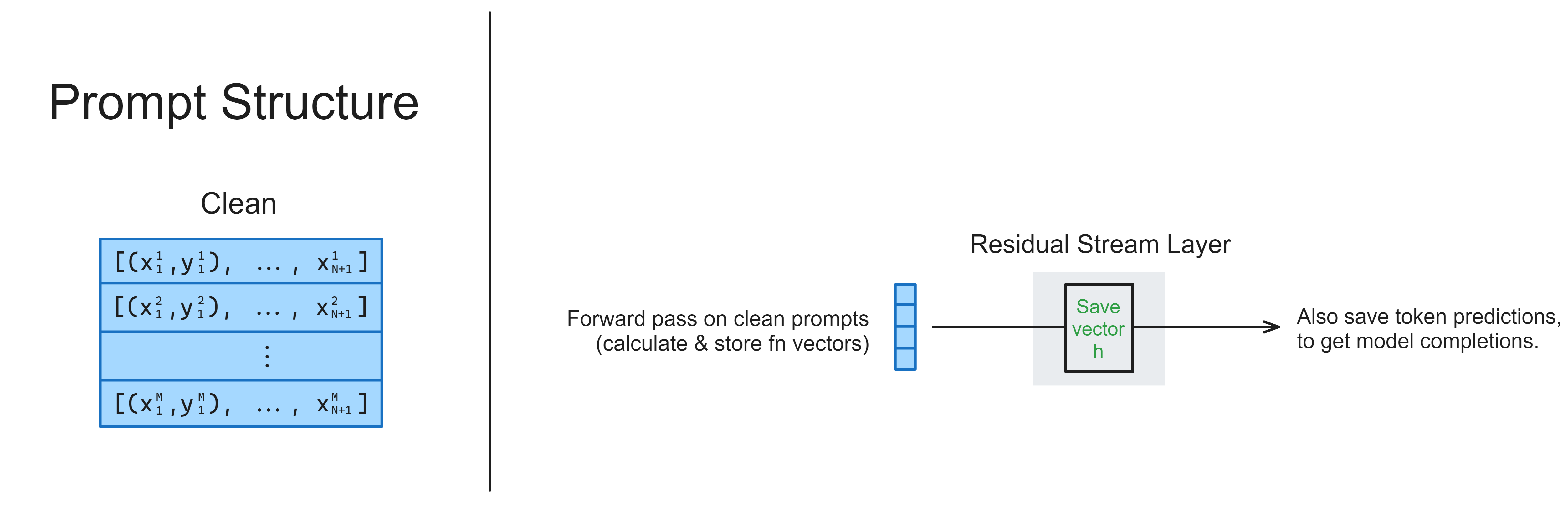
You should only return the residual stream values for the very last sequence position in each prompt, i.e. the last -1 token (where the model makes the antonym prediction), and same for the completions.
Help - I'm not sure how to run (and index into) a batch of inputs.
If we pass a list of strings to the generator.invoke function, this will be tokenized with padding automatically.
The type of padding which is applied is left padding, meaning if you index at sequence position -1, this will get the final token in the prompt for all prompts in the list, even if the prompts have different lengths.
def calculate_h(
model: LanguageModel, dataset: ICLDataset, layer: int = -1
) -> tuple[list[str], Tensor]:
"""
Averages over the model's hidden representations on each of the prompts in `dataset` at layer
`layer`, to produce a single vector `h`.
Inputs:
model: LanguageModel
the transformer you're doing this computation with
dataset: ICLDataset
the dataset whose prompts `dataset.prompts` you're extracting the activations from (at
the last seq pos)
layer: int
the layer you're extracting activations from
Returns:
completions: list[str]
list of the model's next-token predictions (i.e. the strings the model predicts to
follow the last token)
h: Tensor
average hidden state tensor at final sequence position, of shape (d_model,)
"""
raise NotImplementedError()
tests.test_calculate_h(calculate_h, model)
Solution
def calculate_h(
model: LanguageModel, dataset: ICLDataset, layer: int = -1
) -> tuple[list[str], Tensor]:
"""
Averages over the model's hidden representations on each of the prompts in dataset at layer
layer, to produce a single vector h.
Inputs:
model: LanguageModel
the transformer you're doing this computation with
dataset: ICLDataset
the dataset whose prompts dataset.prompts you're extracting the activations from (at
the last seq pos)
layer: int
the layer you're extracting activations from
Returns:
completions: list[str]
list of the model's next-token predictions (i.e. the strings the model predicts to
follow the last token)
h: Tensor
average hidden state tensor at final sequence position, of shape (d_model,)
"""
with model.trace(dataset.prompts, remote=REMOTE):
h = model.transformer.h[layer].output[0][:, -1].mean(dim=0).save()
logits = model.lm_head.output[:, -1]
next_tok_id = logits.argmax(dim=-1).save()
completions = model.tokenizer.batch_decode(next_tok_id)
return completions, h
We've provided you with a helper function, which displays the model's output on the antonym dataset (and highlights the examples where the model's prediction is correct). Note, we're using the repr function, because a lot of the completions are line breaks, and this helps us see them more clearly!
If the antonyms dataset was constructed well, you should find that the model's completion is correct most of the time, and most of its mistakes are either copying (e.g. predicting wet -> wet rather than wet -> dry) or understandable completions which shouldn't really be considered mistakes (e.g. predicting right -> left rather than right -> wrong). If we were being rigorous, we'd want to filter this dataset to make sure it only contains examples where the model can correctly perform the task - but for these exercises, we won't worry about this.
def display_model_completions_on_antonyms(
model: LanguageModel,
dataset: ICLDataset,
completions: list[str],
num_to_display: int = 20,
) -> None:
table = Table(
"Prompt (tuple representation)",
"Model's completion\n(green=correct)",
"Correct completion",
title="Model's antonym completions",
)
for i in range(min(len(completions), num_to_display)):
# Get model's completion, and correct completion
completion = completions[i]
correct_completion = dataset.completions[i]
correct_completion_first_token = model.tokenizer.tokenize(correct_completion)[0].replace(
"Ġ", " "
)
seq = dataset.seqs[i]
# Color code the completion based on whether it's correct
is_correct = completion == correct_completion_first_token
completion = f"[b green]{repr(completion)}[/]" if is_correct else repr(completion)
table.add_row(str(seq), completion, repr(correct_completion))
rprint(table)
# Get uncorrupted dataset
dataset = ICLDataset(ANTONYM_PAIRS, size=20, n_prepended=2)
# Getting it from layer 12, as in the description in section 2.1 of paper
model_completions, h = calculate_h(model, dataset, layer=12)
# Displaying the output
display_model_completions_on_antonyms(model, dataset, model_completions)
Click to see the expected output
Model's antonym completions ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┓ ┃ ┃ Model's completion ┃ ┃ ┃ Prompt (tuple representation) ┃ (green=correct) ┃ Correct completion ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━┩ │ (right, left), (maximum, minimum), melt -> │ ' cast' │ ' freeze' │ │ (minimum, maximum), (old, new), punishment -> │ ' reward' │ ' reward' │ │ (arrogant, humble), (blunt, sharp), compulsory -> │ ' optional' │ ' voluntary' │ │ (inside, outside), (freeze, melt), full -> │ ' empty' │ ' empty' │ │ (reject, accept), (awake, asleep), dusk -> │ ' dawn' │ ' dawn' │ │ (invisible, visible), (punishment, reward), heavy -> │ ' light' │ ' light' │ │ (victory, defeat), (forward, backward), young -> │ ' old' │ ' old' │ │ (up, down), (compulsory, voluntary), right -> │ ' wrong' │ ' wrong' │ │ (open, closed), (domestic, foreign), brave -> │ ' cowardly' │ ' cowardly' │ │ (under, over), (past, future), increase -> │ ' decrease' │ ' decrease' │ │ (inside, outside), (melt, freeze), over -> │ ' under' │ ' under' │ │ (solid, liquid), (backward, forward), open -> │ ' closed' │ ' closed' │ │ (optimist, pessimist), (invisible, visible), brave -> │ ' cowardly' │ ' cowardly' │ │ (noisy, quiet), (sell, buy), north -> │ ' south' │ ' south' │ │ (guilty, innocent), (birth, death), victory -> │ ' defeat' │ ' defeat' │ │ (answer, question), (noisy, quiet), ancient -> │ ' modern' │ ' modern' │ │ (on, off), (success, failure), flexible -> │ ' rigid' │ ' rigid' │ │ (junior, senior), (arrive, depart), punishment -> │ ' reward' │ ' reward' │ │ (loose, tight), (learn, teach), new -> │ ' new' │ ' old' │ │ (introduce, remove), (deficiency, quality), wet -> │ ' wet' │ ' dry' │ └───────────────────────────────────────────────────────┴────────────────────┴────────────────────┘
Using multiple invokes
Another cool feature of nnsight is the ability to run multiple different batches through the model at once (or the same batch multiple times) in a way which leads to very clean syntax for doing causal interventions. Rather than doing something like this:
with model.trace(inputs, remote=REMOTE):
# some causal interventions
we can write a double-nested context manager:
with model.trace(remote=REMOTE) as tracer:
with tracer.invoke(inputs):
# some causal interventions
with tracer.invoke(other_inputs):
# some other causal interventions
Both inputs will be run together in parallel, and proxies defined within one tracer.invoke block can be used in another. A common use-case is to have clean and corrupted inputs, so we can patch from one to the other and get both outputs all in a single forward pass:
with model.trace(remote=REMOTE) as tracer:
with tracer.invoke(clean_inputs):
# extract clean activations
clean_activations = model.transformer.h[10].output[0]
with tracer.invoke(corrupted_inputs):
# patch clean into corrupted
model.transformer.h[10].output[0][:] = clean_activations
You'll do something like this in a later exercise. However for your first exercise (immediately below), you'll only be intervening with vectors that are defined outside of your context manager.
One important thing to watch out for - make sure you're not using your proxy before its being defined! For example, if you were extracting clean_activations from model.transformer.h[10] but then intervening with it on model.transformer.h[9], this couldn't be done in parallel (you'd need to first extract the clean activations, then run the patched forward pass). Doing this should result in a warning message, but may pass silently in some cases - so you need to be extra vigilant!
Exercise - intervene with $h$
You should fill in the function intervene_with_h below. This will involve:
- Run two forward passes (within the same context manager) on a zero-shot dataset:
- One with no intervention (i.e. the residual stream is unchanged),
- One with an intervention using
h(i.e.his added to the residual stream at the layer it was taken from).
- Return the completions for no intervention and intervention cases respectively (see docstring).
The diagram below shows how all of this should work, when combined with the calculate_h function.
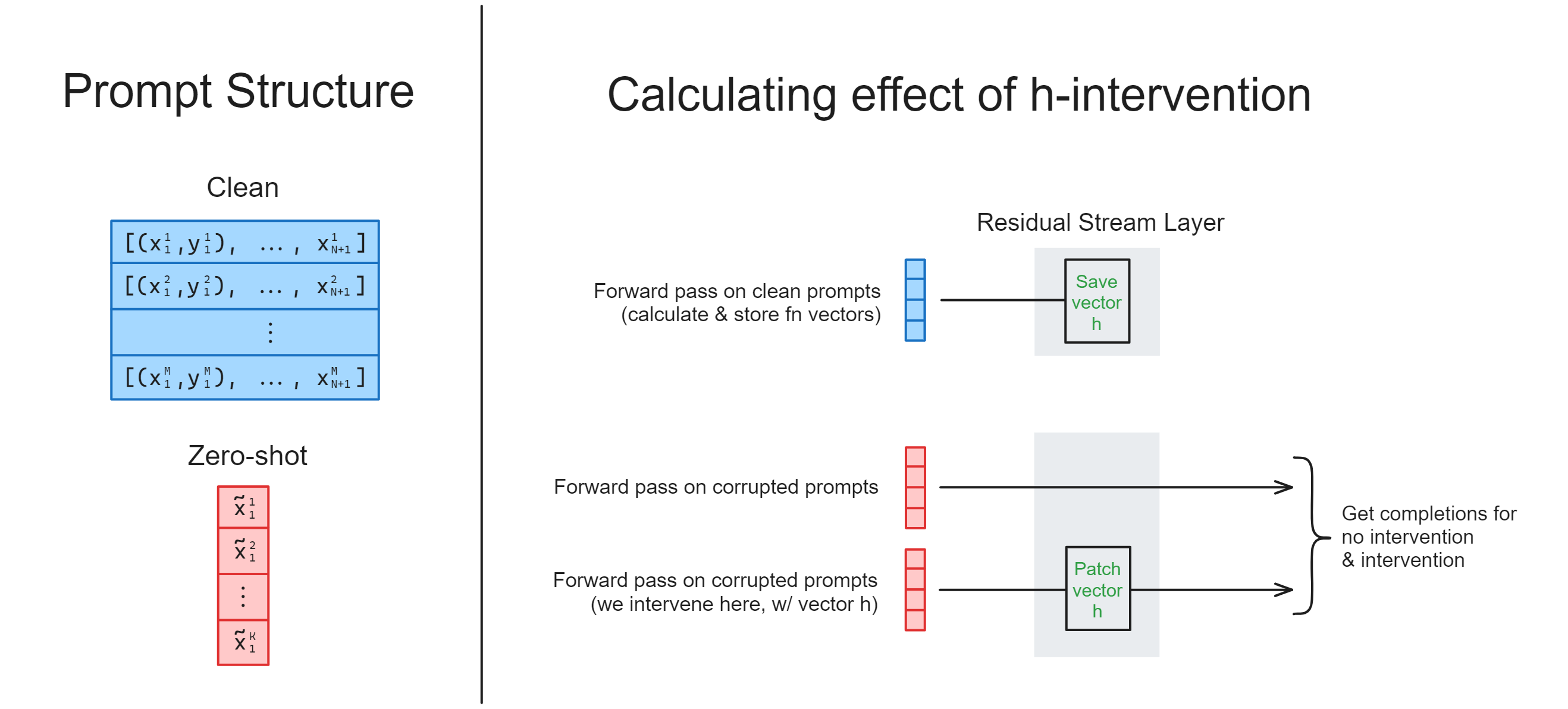
Hint - you can use tokenizer.batch_decode to turn a list of tokens into a list of strings.
Help - I'm not sure how best to get both the no-intervention and intervention completions.
You can use with tracer.invoke... more than once within the same context manager, in order to add to your batch. This will eventually give you output of shape (2*N, seq_len), which can then be indexed and reshaped to get the completions in the no intervention & intervention cases respectively.
Help - I'm not sure how to intervene on the hidden state.
First, you can define the tensor of hidden states (i.e. using .output[0], like you've done before).
Then, you can add to this tensor directly (or add to some indexed version of it). You can use inplace operations (i.e. tensor += h) or redefining the tensor (i.e. tensor = tensor + h); either work.
def intervene_with_h(
model: LanguageModel,
zero_shot_dataset: ICLDataset,
h: Tensor,
layer: int,
remote: bool = REMOTE,
) -> tuple[list[str], list[str]]:
"""
Extracts the vector `h` using previously defined function, and intervenes by adding `h` to the
residual stream of a set of generated zero-shot prompts.
Inputs:
model: the model we're using to generate completions
zero_shot_dataset: the dataset of zero-shot prompts which we'll intervene on, using the
`h`-vector
h: the `h`-vector we'll be adding to the residual stream
layer: the layer we'll be extracting the `h`-vector from
remote: whether to run the forward pass on the remote server (used for running test code)
Returns:
completions_zero_shot: list of string completions for the zero-shot prompts, without
intervention using the h-vector
completions_intervention: list of string completions for the zero-shot prompts, with
intervention using the h-vector
"""
raise NotImplementedError()
tests.test_intervene_with_h(intervene_with_h, model, h, ANTONYM_PAIRS, REMOTE)
Solution
def intervene_with_h(
model: LanguageModel,
zero_shot_dataset: ICLDataset,
h: Tensor,
layer: int,
remote: bool = REMOTE,
) -> tuple[list[str], list[str]]:
"""
Extracts the vector h using previously defined function, and intervenes by adding h to the
residual stream of a set of generated zero-shot prompts.
Inputs:
model: the model we're using to generate completions
zero_shot_dataset: the dataset of zero-shot prompts which we'll intervene on, using the
h-vector
h: the h-vector we'll be adding to the residual stream
layer: the layer we'll be extracting the h-vector from
remote: whether to run the forward pass on the remote server (used for running test code)
Returns:
completions_zero_shot: list of string completions for the zero-shot prompts, without
intervention using the h-vector
completions_intervention: list of string completions for the zero-shot prompts, with
intervention using the h-vector
"""
with model.trace(remote=remote) as tracer:
# First, run a forward pass where we don't intervene, just save token id completions
with tracer.invoke(zero_shot_dataset.prompts):
token_completions_zero_shot = model.lm_head.output[:, -1].argmax(dim=-1).save()
# Next, run a forward pass on the zero-shot prompts where we do intervene
with tracer.invoke(zero_shot_dataset.prompts):
# Add the h-vector to the residual stream, at the last sequence position
hidden_states = model.transformer.h[layer].output[0]
hidden_states[:, -1] += h
# Also save completions
token_completions_intervention = model.lm_head.output[:, -1].argmax(dim=-1).save()
# Decode to get the string tokens
completions_zero_shot = model.tokenizer.batch_decode(token_completions_zero_shot)
completions_intervention = model.tokenizer.batch_decode(token_completions_intervention)
return completions_zero_shot, completions_intervention
Run the code below to calculate completions for the function.
Note, it's very important that we set a different random seed for the zero shot dataset, otherwise we'll be intervening on examples which were actually in the dataset we used to compute $h$!
layer = 12
dataset = ICLDataset(ANTONYM_PAIRS, size=20, n_prepended=3, seed=0)
zero_shot_dataset = ICLDataset(ANTONYM_PAIRS, size=20, n_prepended=0, seed=1)
# Run previous function to get h-vector
h = calculate_h(model, dataset, layer=layer)[1]
# Run new function to intervene with h-vector
completions_zero_shot, completions_intervention = intervene_with_h(
model, zero_shot_dataset, h, layer=layer
)
print("Zero-shot completions: ", completions_zero_shot)
print("Completions with intervention: ", completions_intervention)
Click to see the expected output
Zero-shot completions: [' minimum', ' arrogant', ' inside', ' reject', ' invisible', ' victory', ' up', ' open', ' under', ' inside', ' solid', '\n', ' noisy', ' guilty', ' yes', ' I', ' senior', ' loose', ' introduce', ' guilty'] Completions with intervention: [' maximum', ' arrogant', ' outside', ' reject', ' invisible', ' victory', ' down', ' closed', ' under', ' outside', ' solid', ' optim', ' noisy', ' guilty', ' answer', ' on', ' senior', ' loose', ' introduce', ' guilty']
Next, run the code below to visualise the completions in a table. You should see:
- 0% (or near zero) correct completions on the zero-shot prompt with no intervention, because the model usually just copies the first and only word in the prompt
- 25-50% correct completions on the zero-shot prompt with intervention
def display_model_completions_on_h_intervention(
dataset: ICLDataset,
completions: list[str],
completions_intervention: list[str],
num_to_display: int = 20,
) -> None:
table = Table(
"Prompt",
"Model's completion\n(no intervention)",
"Model's completion\n(intervention)",
"Correct completion",
title="Model's antonym completions",
)
for i in range(min(len(completions), num_to_display)):
completion_ni = completions[i]
completion_i = completions_intervention[i]
correct_completion = dataset.completions[i]
correct_completion_first_token = tokenizer.tokenize(correct_completion)[0].replace("Ġ", " ")
seq = dataset.seqs[i]
# Color code the completion based on whether it's correct
is_correct = completion_i == correct_completion_first_token
completion_i = f"[b green]{repr(completion_i)}[/]" if is_correct else repr(completion_i)
table.add_row(str(seq), repr(completion_ni), completion_i, repr(correct_completion))
rprint(table)
display_model_completions_on_h_intervention(
zero_shot_dataset, completions_zero_shot, completions_intervention
)
Click to see the expected output
Model's antonym completions ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┓ ┃ ┃ Model's completion ┃ Model's completion ┃ ┃ ┃ Prompt ┃ (no intervention) ┃ (intervention) ┃ Correct completion ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━┩ │ minimum -> │ ' minimum' │ ' maximum' │ ' maximum' │ │ arrogant -> │ ' arrogant' │ ' arrogant' │ ' humble' │ │ inside -> │ ' inside' │ ' outside' │ ' outside' │ │ reject -> │ ' reject' │ ' reject' │ ' accept' │ │ invisible -> │ ' invisible' │ ' invisible' │ ' visible' │ │ victory -> │ ' victory' │ ' victory' │ ' defeat' │ │ up -> │ ' up' │ ' down' │ ' down' │ │ open -> │ ' open' │ ' closed' │ ' closed' │ │ under -> │ ' under' │ ' under' │ ' over' │ │ inside -> │ ' inside' │ ' outside' │ ' outside' │ │ solid -> │ ' solid' │ ' solid' │ ' liquid' │ │ optimist -> │ '\n' │ ' optim' │ ' pessimist' │ │ noisy -> │ ' noisy' │ ' noisy' │ ' quiet' │ │ guilty -> │ ' guilty' │ ' guilty' │ ' innocent' │ │ answer -> │ ' yes' │ ' answer' │ ' question' │ │ on -> │ ' I' │ ' on' │ ' off' │ │ junior -> │ ' senior' │ ' senior' │ ' senior' │ │ loose -> │ ' loose' │ ' loose' │ ' tight' │ │ introduce -> │ ' introduce' │ ' introduce' │ ' remove' │ │ innocent -> │ ' guilty' │ ' guilty' │ ' guilty' │ └──────────────┴────────────────────┴────────────────────┴────────────────────┘
Exercise - combine the last two functions
One great feature of the nnsight library is its ability to parallelize forward passes and perform complex interventions within a single context manager.
In the code above, we had one function to extract the hidden states from the model, and another function where we intervened with those hidden states. But we can actually do both at once: we can compute $h$ within our forward pass, and then intervene with it on a different forward pass (using our zero-shot prompts), all within the same model.trace context manager. In other words, we'll be using with tracer.invoke... three times in this context manager.
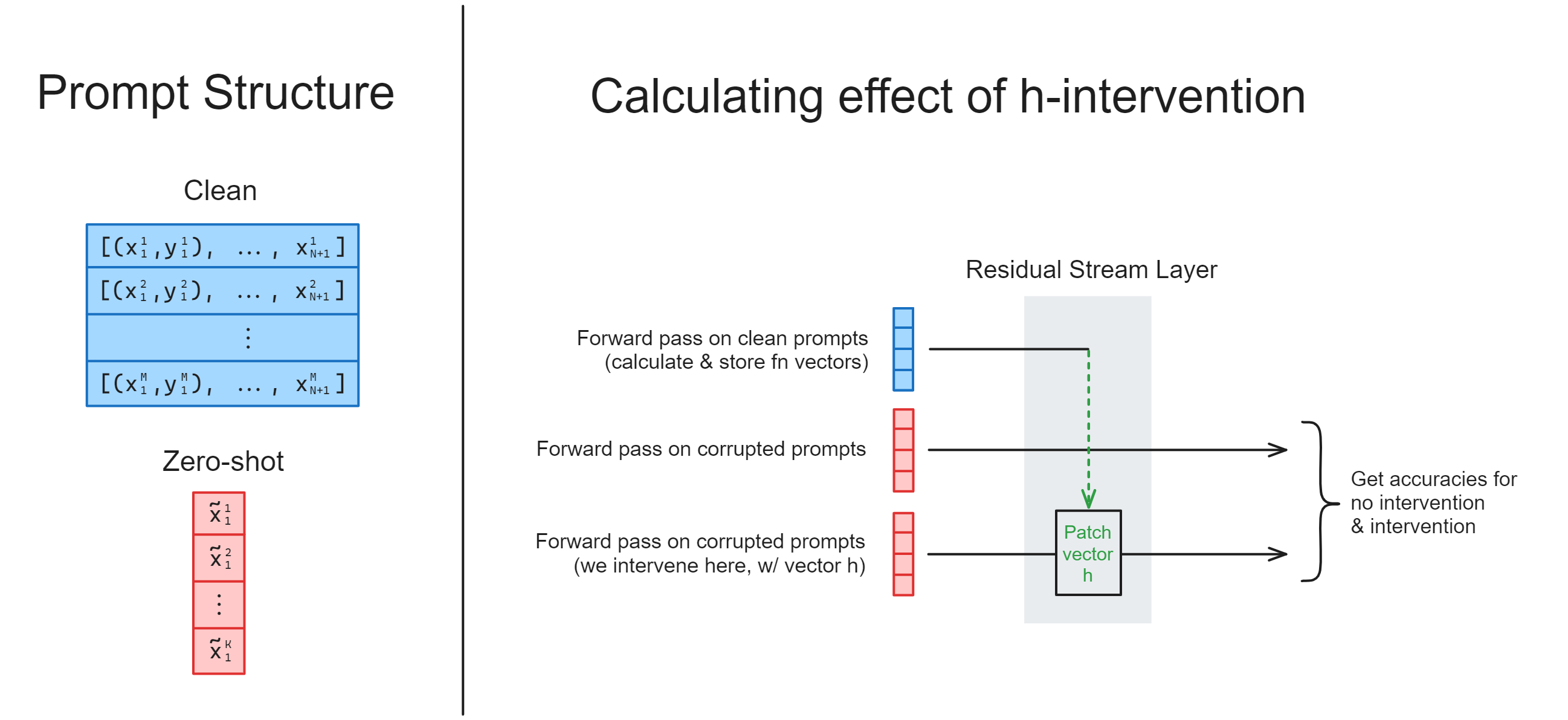
You should fill in the calculate_h_and_intervene function below, to do this. Mostly, this should involve combining your calculate_h and intervene_with_h functions, and wrapping the forward passes in the same context manager (plus a bit of code rewriting).
Your output should be exactly the same as before (since the ICLDataset class is deterministic), hence we've not provided test functions in this case - you can just compare the table you get to the one before! However, this time around your code should run twice as fast, because you're batching the operations of "compute $h$" and "intervene with $h$" together into a single forward pass.
Help - I'm not sure how to use the h vector inside the context manager.
You extract h the same way as before, but you don't need to save it. It is kept as a proxy. You can still use it later in the context manager, just like it actually was a tensor.
You shouldn't have to .save() anything inside your context manager, other than the token completions.
Help - If I want to add x vector to a slice of my hidden state tensor h, is h[slice]+=x the same as h2 = h[slice], h2 += x?
No, only h[slice]+=x does what you want. This is because when doing h2 = h[slice], h2 += x, the modification line h2 += x is no longer modifying the original tensor h, but a different tensorh2. In contrast, h[slice]+=x keeps the original tensor h in the modification line.
A good rule to keep in mind is: If you're trying to modify a tensor some in-place operation, make sure that tensor is in the actual modification line!
def calculate_h_and_intervene(
model: LanguageModel,
dataset: ICLDataset,
zero_shot_dataset: ICLDataset,
layer: int,
) -> tuple[list[str], list[str]]:
"""
Extracts the vector `h`, intervenes by adding `h` to the residual stream of a set of generated
zero-shot prompts, all within the same forward pass. Returns the completions from this
intervention.
Inputs:
model: LanguageModel
the model we're using to generate completions
dataset: ICLDataset
the dataset of clean prompts from which we'll extract the `h`-vector
zero_shot_dataset: ICLDataset
the dataset of zero-shot prompts which we'll intervene on, using the `h`-vector
layer: int
the layer we'll be extracting the `h`-vector from
Returns:
completions_zero_shot: list[str]
list of string completions for the zero-shot prompts, without intervention
completions_intervention: list[str]
list of string completions for the zero-shot prompts, with h-intervention
"""
raise NotImplementedError()
dataset = ICLDataset(ANTONYM_PAIRS, size=20, n_prepended=3, seed=0)
zero_shot_dataset = ICLDataset(ANTONYM_PAIRS, size=20, n_prepended=0, seed=1)
completions_zero_shot, completions_intervention = calculate_h_and_intervene(
model, dataset, zero_shot_dataset, layer=layer
)
display_model_completions_on_h_intervention(
zero_shot_dataset, completions_zero_shot, completions_intervention
)
Click to see the expected output
Model's antonym completions ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┓ ┃ ┃ Model's completion ┃ Model's completion ┃ ┃ ┃ Prompt ┃ (no intervention) ┃ (intervention) ┃ Correct completion ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━┩ │ minimum -> │ ' minimum' │ ' maximum' │ ' maximum' │ │ arrogant -> │ ' arrogant' │ ' arrogant' │ ' humble' │ │ inside -> │ ' inside' │ ' outside' │ ' outside' │ │ reject -> │ ' reject' │ ' reject' │ ' accept' │ │ invisible -> │ ' invisible' │ ' invisible' │ ' visible' │ │ victory -> │ ' victory' │ ' victory' │ ' defeat' │ │ up -> │ ' up' │ ' down' │ ' down' │ │ open -> │ ' open' │ ' closed' │ ' closed' │ │ under -> │ ' under' │ ' under' │ ' over' │ │ inside -> │ ' inside' │ ' outside' │ ' outside' │ │ solid -> │ ' solid' │ ' solid' │ ' liquid' │ │ optimist -> │ '\n' │ ' optim' │ ' pessimist' │ │ noisy -> │ ' noisy' │ ' noisy' │ ' quiet' │ │ guilty -> │ ' guilty' │ ' guilty' │ ' innocent' │ │ answer -> │ ' yes' │ ' answer' │ ' question' │ │ on -> │ ' I' │ ' on' │ ' off' │ │ junior -> │ ' senior' │ ' senior' │ ' senior' │ │ loose -> │ ' loose' │ ' loose' │ ' tight' │ │ introduce -> │ ' introduce' │ ' introduce' │ ' remove' │ │ innocent -> │ ' innocent' │ ' guilty' │ ' guilty' │ └──────────────┴────────────────────┴────────────────────┴────────────────────┘
Solution
def calculate_h_and_intervene(
model: LanguageModel,
dataset: ICLDataset,
zero_shot_dataset: ICLDataset,
layer: int,
) -> tuple[list[str], list[str]]:
"""
Extracts the vector h, intervenes by adding h to the residual stream of a set of generated
zero-shot prompts, all within the same forward pass. Returns the completions from this
intervention.
Inputs:
model: LanguageModel
the model we're using to generate completions
dataset: ICLDataset
the dataset of clean prompts from which we'll extract the h-vector
zero_shot_dataset: ICLDataset
the dataset of zero-shot prompts which we'll intervene on, using the h-vector
layer: int
the layer we'll be extracting the h-vector from
Returns:
completions_zero_shot: list[str]
list of string completions for the zero-shot prompts, without intervention
completions_intervention: list[str]
list of string completions for the zero-shot prompts, with h-intervention
"""
with model.trace(remote=REMOTE) as tracer:
with tracer.invoke(dataset.prompts):
h = model.transformer.h[layer].output[0][:, -1].mean(dim=0)
with tracer.invoke(zero_shot_dataset.prompts):
clean_tokens = model.lm_head.output[:, -1].argmax(dim=-1).save()
with tracer.invoke(zero_shot_dataset.prompts):
hidden = model.transformer.h[layer].output[0]
hidden[:, -1] += h
intervene_tokens = model.lm_head.output[:, -1].argmax(dim=-1).save()
completions_zero_shot = tokenizer.batch_decode(clean_tokens)
completions_intervention = tokenizer.batch_decode(intervene_tokens)
return completions_zero_shot, completions_intervention
Exercise - compute change in accuracy
So far, all we've done is look at the most likely completions, and see what fraction of the time these were correct. But our forward pass doesn't just give us token completions, it gives us logits too!
You should now rewrite the calculate_h_and_intervene function so that, rather than returning two lists of string completions, it returns two lists of floats containing the logprobs assigned by the model to the correct antonym in the no intervention / intervention cases respectively.
Help - I don't know how to get the correct logprobs from the logits.
First, apply log softmax to the logits, to get logprobs.
Second, you can use tokenizer(dataset.completions)["input_ids"] to get the token IDs of the correct completions. (Gotcha - some words might be tokenized into multiple tokens, so make sure you're just picking the first token ID for each completion.)
Note - we recommend doing all this inside the context manager, then saving and returning just the correct logprobs not all the logits (this means less to download from the server!).
def calculate_h_and_intervene_logprobs(
model: LanguageModel,
dataset: ICLDataset,
zero_shot_dataset: ICLDataset,
layer: int,
) -> tuple[list[float], list[float]]:
"""
Extracts the vector `h`, intervenes by adding `h` to the residual stream of a set of generated
zero-shot prompts, all within the same forward pass. Returns the logprobs on correct tokens from
this intervention.
Inputs:
model: LanguageModel
the model we're using to generate completions
dataset: ICLDataset
the dataset of clean prompts from which we'll extract the `h`-vector
zero_shot_dataset: ICLDataset
the dataset of zero-shot prompts which we'll intervene on, using the `h`-vector
layer: int
the layer we'll be extracting the `h`-vector from
Returns:
correct_logprobs: list[float]
list of correct-token logprobs for the zero-shot prompts, without intervention
correct_logprobs_intervention: list[float]
list of correct-token logprobs for the zero-shot prompts, with h-intervention
"""
raise NotImplementedError()
Solution
def calculate_h_and_intervene_logprobs(
model: LanguageModel,
dataset: ICLDataset,
zero_shot_dataset: ICLDataset,
layer: int,
) -> tuple[list[float], list[float]]:
"""
Extracts the vector h, intervenes by adding h to the residual stream of a set of generated
zero-shot prompts, all within the same forward pass. Returns the logprobs on correct tokens from
this intervention.
Inputs:
model: LanguageModel
the model we're using to generate completions
dataset: ICLDataset
the dataset of clean prompts from which we'll extract the h-vector
zero_shot_dataset: ICLDataset
the dataset of zero-shot prompts which we'll intervene on, using the h-vector
layer: int
the layer we'll be extracting the h-vector from
Returns:
correct_logprobs: list[float]
list of correct-token logprobs for the zero-shot prompts, without intervention
correct_logprobs_intervention: list[float]
list of correct-token logprobs for the zero-shot prompts, with h-intervention
"""
correct_completion_ids = [
toks[0] for toks in tokenizer(zero_shot_dataset.completions)["input_ids"]
]
with model.trace(remote=REMOTE) as tracer:
with tracer.invoke(dataset.prompts):
h = model.transformer.h[layer].output[0][:, -1].mean(dim=0)
with tracer.invoke(zero_shot_dataset.prompts):
clean_logprobs = model.lm_head.output.log_softmax(dim=-1)[
range(len(zero_shot_dataset)), -1, correct_completion_ids
].save()
with tracer.invoke(zero_shot_dataset.prompts):
hidden = model.transformer.h[layer].output[0]
hidden[:, -1] += h
intervene_logprobs = model.lm_head.output.log_softmax(dim=-1)[
range(len(zero_shot_dataset)), -1, correct_completion_ids
].save()
return clean_logprobs, intervene_logprobs
When you run the code below, it will display the log-probabilities (highlighting green when they increase from the zero-shot case). You should find that in every sequence, the logprobs on the correct token increase in the intervention. This helps make something clear - even if the maximum-likelihood token doesn't change, this doesn't mean that the intervention isn't having a significant effect.
def display_model_logprobs_on_h_intervention(
dataset: ICLDataset,
correct_logprobs_zero_shot: list[float],
correct_logprobs_intervention: list[float],
num_to_display: int = 20,
) -> None:
table = Table(
"Zero-shot prompt",
"Model's logprob\n(no intervention)",
"Model's logprob\n(intervention)",
"Change in logprob",
title="Model's antonym logprobs, with zero-shot h-intervention\n(green = intervention improves accuracy)",
)
for i in range(min(len(correct_logprobs_zero_shot), num_to_display)):
logprob_ni = correct_logprobs_zero_shot[i]
logprob_i = correct_logprobs_intervention[i]
delta_logprob = logprob_i - logprob_ni
zero_shot_prompt = f"{dataset[i].x[0]:>8} -> {dataset[i].y[0]}"
# Color code the logprob based on whether it's increased with this intervention
is_improvement = delta_logprob >= 0
delta_logprob = (
f"[b green]{delta_logprob:+.2f}[/]" if is_improvement else f"{delta_logprob:+.2f}"
)
table.add_row(zero_shot_prompt, f"{logprob_ni:.2f}", f"{logprob_i:.2f}", delta_logprob)
rprint(table)
dataset = ICLDataset(ANTONYM_PAIRS, size=20, n_prepended=3, seed=0)
zero_shot_dataset = ICLDataset(ANTONYM_PAIRS, size=20, n_prepended=0, seed=1)
correct_logprobs_zero_shot, correct_logprobs_intervention = calculate_h_and_intervene_logprobs(
model, dataset, zero_shot_dataset, layer=layer
)
display_model_logprobs_on_h_intervention(
zero_shot_dataset, correct_logprobs_zero_shot, correct_logprobs_intervention
)
Click to see the expected output
Model's antonym logprobs, with zero-shot h-intervention (green = intervention improves accuracy) ┏━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┓ ┃ ┃ Model's logprob ┃ Model's logprob ┃ ┃ ┃ Zero-shot prompt ┃ (no intervention) ┃ (intervention) ┃ Change in logprob ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━┩ │ minimum -> maximum │ -2.75 │ -0.64 │ +2.11 │ │ arrogant -> humble │ -6.19 │ -3.92 │ +2.27 │ │ inside -> outside │ -3.70 │ -0.99 │ +2.72 │ │ reject -> accept │ -3.94 │ -1.98 │ +1.95 │ │ invisible -> visible │ -3.80 │ -1.99 │ +1.80 │ │ victory -> defeat │ -4.41 │ -2.30 │ +2.11 │ │ up -> down │ -3.97 │ -1.26 │ +2.72 │ │ open -> closed │ -5.06 │ -1.43 │ +3.62 │ │ under -> over │ -4.78 │ -3.44 │ +1.34 │ │ inside -> outside │ -3.70 │ -0.99 │ +2.72 │ │ solid -> liquid │ -5.53 │ -3.02 │ +2.52 │ │ optimist -> pessimist │ -6.41 │ -3.41 │ +3.00 │ │ noisy -> quiet │ -4.28 │ -3.34 │ +0.94 │ │ guilty -> innocent │ -4.94 │ -2.75 │ +2.19 │ │ answer -> question │ -5.09 │ -3.91 │ +1.19 │ │ on -> off │ -7.00 │ -4.31 │ +2.69 │ │ junior -> senior │ -2.25 │ -1.07 │ +1.18 │ │ loose -> tight │ -5.56 │ -2.98 │ +2.58 │ │ introduce -> remove │ -7.50 │ -6.19 │ +1.31 │ │ innocent -> guilty │ -2.86 │ -1.67 │ +1.19 │ └───────────────────────┴───────────────────┴─────────────────┴───────────────────┘