[1.2] Intro to Mechanistic Interpretability: TransformerLens & induction circuits
Please send any problems / bugs on the #errata channel in the Slack group, and ask any questions on the dedicated channels for this chapter of material.
If you want to change to dark mode, you can do this by clicking the three horizontal lines in the top-right, then navigating to Settings → Theme.
Links to all other chapters: (0) Fundamentals, (1) Transformer Interpretability, (2) RL.

Introduction
These pages are designed to get you introduced to the core concepts of mechanistic interpretability, via Neel Nanda's TransformerLens library.
Most of the sections are constructed in the following way:
- A particular feature of TransformerLens is introduced.
- You are given an exercise, in which you have to apply the feature.
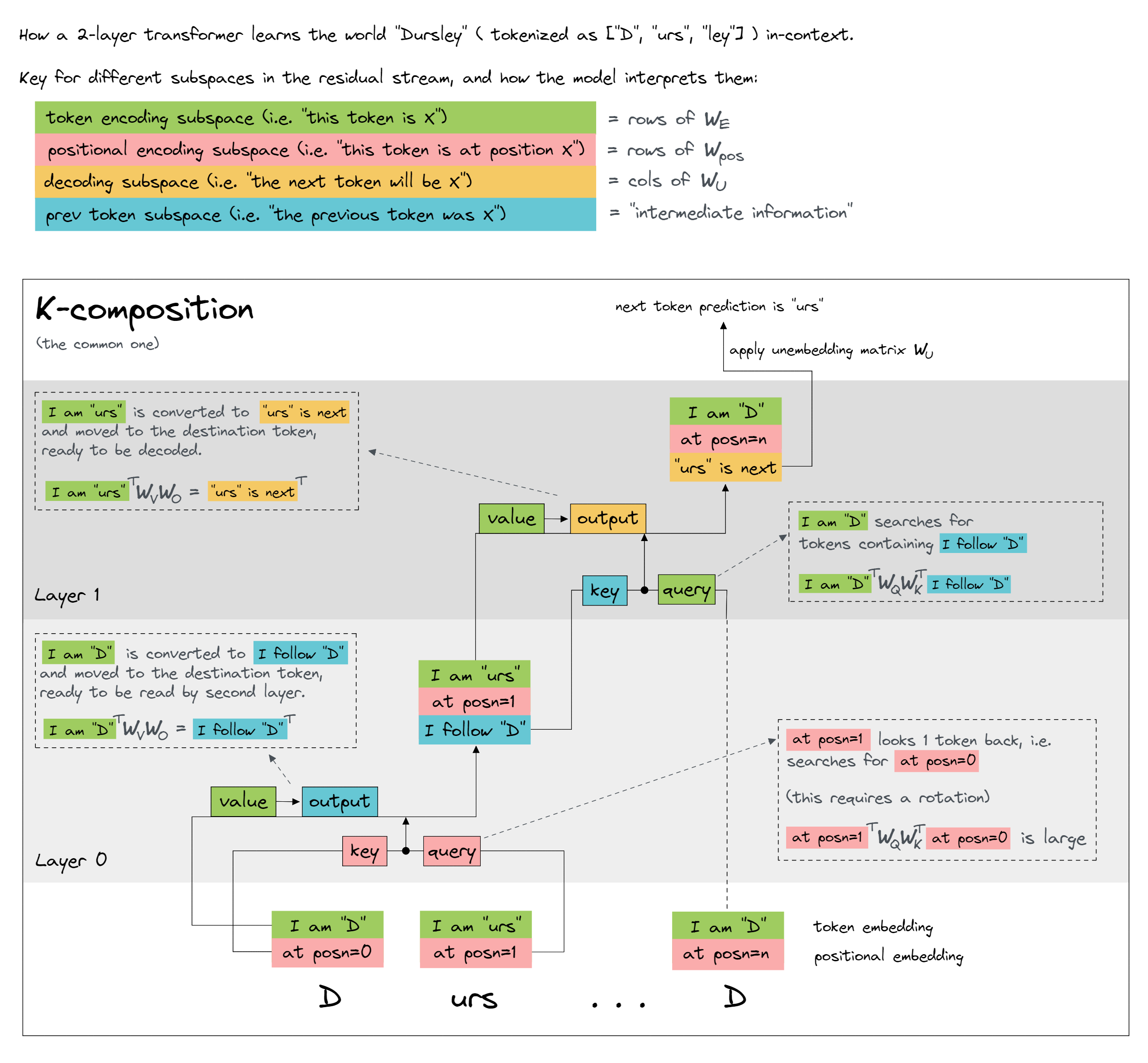
The running theme of the exercises is induction circuits. Induction circuits are a particular type of circuit in a transformer, which can perform basic in-context learning. You should read the corresponding section of Neel's glossary, before continuing. This LessWrong post might also help; it contains some diagrams (like the one below) which walk through the induction mechanism step by step.
Each exercise will have a difficulty and importance rating out of 5, as well as an estimated maximum time you should spend on these exercises and sometimes a short annotation. You should interpret the ratings & time estimates relatively (e.g. if you find yourself spending about 50% longer on the exercises than the time estimates, adjust accordingly). Please do skip exercises / look at solutions if you don't feel like they're important enough to be worth doing, and you'd rather get to the good stuff!
For a lecture on the material today, which provides some high-level understanding before you dive into the material, watch the video below:
Content & Learning Objectives
1️⃣ TransformerLens: Introduction
This section is designed to get you up to speed with the TransformerLens library. You'll learn how to load and run models, and learn about the shared architecture template for all of these models (the latter of which should be familiar to you if you've already done the exercises that come before these, since many of the same design principles are followed).
Learning Objectives
- Load and run a
HookedTransformermodel- Understand the basic architecture of these models
- Use the model's tokenizer to convert text to tokens, and vice versa
- Know how to cache activations, and to access activations from the cache
- Use
circuitsvisto visualise attention heads
2️⃣ Finding induction heads
Here, you'll learn about induction heads, how they work and why they are important. You'll also learn how to identify them from the characteristic induction head stripe in their attention patterns when the model input is a repeating sequence.
Learning Objectives
- Understand what induction heads are, and the algorithm they are implementing
- Inspect activation patterns to identify basic attention head patterns, and write your own functions to detect attention heads for you
- Identify induction heads by looking at the attention patterns produced from a repeating random sequence
3️⃣ TransformerLens: Hooks
Next, you'll learn about hooks, which are a great feature of TransformerLens allowing you to access and intervene on activations within the model. We will mainly focus on the basics of hooks and using them to access activations (we'll mainly save the causal interventions for the later IOI exercises). You will also build some tools to perform logit attribution within your model, so you can identify which components are responsible for your model's performance on certain tasks.
Learning Objectives
- Understand what hooks are, and how they are used in TransformerLens
- Use hooks to access activations, process the results, and write them to an external tensor
- Build tools to perform attribution, i.e. detecting which components of your model are responsible for performance on a given task
- Understand how hooks can be used to perform basic interventions like ablation
4️⃣ Reverse-engineering induction circuits
Lastly, these exercises show you how you can reverse-engineer a circuit by looking directly at a transformer's weights (which can be considered a "gold standard" of interpretability; something not possible in every situation). You'll examine QK and OV circuits by multiplying through matrices (and learn how the FactoredMatrix class makes matrices like these much easier to analyse). You'll also look for evidence of composition between two induction heads, and once you've found it then you'll investigate the functionality of the full circuit formed from this composition.
Learning Objectives
- Understand the difference between investigating a circuit by looking at activation patterns, and reverse-engineering a circuit by looking directly at the weights
- Use the factored matrix class to inspect the QK and OV circuits within an induction circuit
- Perform further exploration of induction circuits: composition scores, and targeted ablations
Setup code
import functools
import sys
from pathlib import Path
from typing import Callable
import circuitsvis as cv
import einops
import numpy as np
import torch as t
import torch.nn as nn
from eindex import eindex
from IPython.display import display
from jaxtyping import Float, Int
from torch import Tensor
from tqdm import tqdm
from transformer_lens import (
ActivationCache,
FactoredMatrix,
HookedTransformer,
HookedTransformerConfig,
utils,
)
from transformer_lens.hook_points import HookPoint
device = t.device("mps" if t.backends.mps.is_available() else "cuda" if t.cuda.is_available() else "cpu")
# Make sure exercises are in the path
chapter = "chapter1_transformer_interp"
section = "part2_intro_to_mech_interp"
root_dir = next(p for p in Path.cwd().parents if (p / chapter).exists())
exercises_dir = root_dir / chapter / "exercises"
section_dir = exercises_dir / section
if str(exercises_dir) not in sys.path:
sys.path.append(str(exercises_dir))
import part2_intro_to_mech_interp.tests as tests
from plotly_utils import (
hist,
imshow,
plot_comp_scores,
plot_logit_attribution,
plot_loss_difference,
)
# Saves computation time, since we don't need it for the contents of this notebook
t.set_grad_enabled(False)
MAIN = __name__ == "__main__"